Unqualified Reservations has a great post dissecting the Wolfram Alpha hubristic User Interface.
Warning: this guy seems to be able to write faster than most people can read. Browse his blog at your peril!
Friday, 2 October 2009
Monday, 21 September 2009
OS and GM SXS for LEJOG in the UK
Translation: Ordnance Survey and Google Maps side-by-side for planning the Land's End-John O'Groats walk in the United Kingdom.
My friend Steve is walking the LEJOG in 2010 (I guess that makes him a LEJOGger - as opposed to the JOGLErs who go North to South). Of course he is blogging about it - doesn't everybody?.
Even better, he's planning his route using Where's The Path, which is a fantastic side-by-side map site for the U.K. It shows Ordnance Survey topographic maps and Google Maps imagery in a cleverly linked view (similar to the VExGM web site I blogged about earlier this year, but even more useful). Here's a link to the most famous location in Britain (but I suspect it doesn't feature in many LEJOG itineraries, unless you're a real anorak for walking).
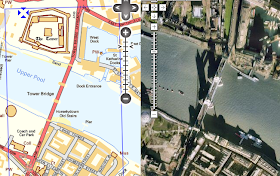
WTP also lets you digitize paths and export them to GPX and KML. Steve is finding the KML export particularly useful, since it allows him to locate all the pubs along the route of his walk.
Now, when is someone going to do this for Canada? All those prospective SJV'ers out there would be overjoyed!
My friend Steve is walking the LEJOG in 2010 (I guess that makes him a LEJOGger - as opposed to the JOGLErs who go North to South). Of course he is blogging about it - doesn't everybody?.
Even better, he's planning his route using Where's The Path, which is a fantastic side-by-side map site for the U.K. It shows Ordnance Survey topographic maps and Google Maps imagery in a cleverly linked view (similar to the VExGM web site I blogged about earlier this year, but even more useful). Here's a link to the most famous location in Britain (but I suspect it doesn't feature in many LEJOG itineraries, unless you're a real anorak for walking).

WTP also lets you digitize paths and export them to GPX and KML. Steve is finding the KML export particularly useful, since it allows him to locate all the pubs along the route of his walk.
Now, when is someone going to do this for Canada? All those prospective SJV'ers out there would be overjoyed!
Tuesday, 15 September 2009
Earn a diploma with JTS!
(No doubt by choosing that title I've exposed by my blog to death by spam filter. Although if the ones with titles like "Increase your performance with JTS!" got through, maybe I'm ok.)
The Kungliga Tekniska högskolan in Sweden (isn't Unicode wonderful?) is offering a course on GIS Architecture. I was happy to see that they're using JTS as a tool for exploring the DE-9IM spatial relationship model, and also as an example of a Open Source geospatial library.
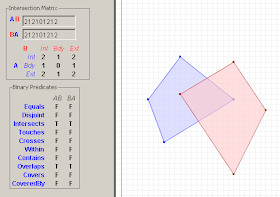
The Kungliga Tekniska högskolan in Sweden (isn't Unicode wonderful?) is offering a course on GIS Architecture. I was happy to see that they're using JTS as a tool for exploring the DE-9IM spatial relationship model, and also as an example of a Open Source geospatial library.

Tuesday, 25 August 2009
JTS - Links to Geometry APIs and papers
Motivated by a thread on the GEOS list about the Boost.Polygon library, I've added some new resources to the JTS web site, including:
Over the years of working with JTS I've read a ton of interesting and sometimes even useful academic papers about aspects of Computational Geometry. I hope to start documenting these on this page, perhaps with some (no doubt opinionated) comments about applicability. A treasure trove for Geometry geeks!
- a list of geometry APIs
- a section of references to papers about topics in Computational Geometry which are relevant to JTS.
Over the years of working with JTS I've read a ton of interesting and sometimes even useful academic papers about aspects of Computational Geometry. I hope to start documenting these on this page, perhaps with some (no doubt opinionated) comments about applicability. A treasure trove for Geometry geeks!
Wednesday, 19 August 2009
Super Zoom Control is really super!
The web mapping site 192.com has a very nice map zoom control which dynamically displays a representative image of the map at the prospective zoom level.
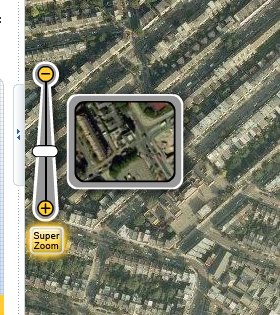
This nicely addresses a problem which has occurred in a few applications I've been involved with recently - how to communicate to the user what a given zoom level actually looks like.
At first I thought the control might be truly dynamic - i.e. pulling a live tile from the centre point of the current map view. But it's actually just a set of tile snippets at a fixed point. Still, it provides a very nice effect. (The dynamic version would be simple to implement, but perhaps would be too slow in actual use, with unpredicatable latency).
Are you listening, OpenLayers?

This nicely addresses a problem which has occurred in a few applications I've been involved with recently - how to communicate to the user what a given zoom level actually looks like.
At first I thought the control might be truly dynamic - i.e. pulling a live tile from the centre point of the current map view. But it's actually just a set of tile snippets at a fixed point. Still, it provides a very nice effect. (The dynamic version would be simple to implement, but perhaps would be too slow in actual use, with unpredicatable latency).
Are you listening, OpenLayers?
Thursday, 6 August 2009
Visualizations of Sorting Algorithms in your browser
Here's a nifty web page which shows a way of visualizing the operation of various common sorting algorithms.
Sample output for Heapsort:

The coolest thing about this of course is the ability to dynamically generate rich graphics in the browser. All hail the HTML5 <canvas> element!
Sample output for Heapsort:

The coolest thing about this of course is the ability to dynamically generate rich graphics in the browser. All hail the HTML5 <canvas> element!
Tuesday, 9 June 2009

Friday, 15 May 2009
UML Sequence Diagrams on the Web
I find the sequence diagram to be one of the most useful UML diagrams - but it's also one of the most fiddly & annoying to generate in a diagramming tool. There's a few reasons for that:
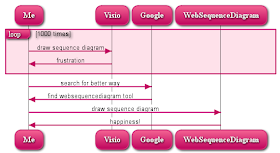
The language supports just about everything you might want - signal types, groups, nesting, notes, lifelines, etc. It outputs in images or as PDF - and it even has cool styles! Here's the idea:
produces
I've blogged about the appeal of specifying UML diagrams using code before. I'm not sure how much traction TextUML is getting - but it's hard to resist the appeal of a web interface, a simple language, and sexy ouput.
Now, if only someone would develop a force-directed web-based state diagram engine...
Note: there's some other alternatives to the websequencediagram tool - the author blogs about them here. The most interesting from my point of view is sdedit, which is open-source and Java-based. It's more powerful, but the language looks a mite complex. (Too bad there's no standard language for describing UML - maybe the Three Amigos should skip a siesta and whip one up.)
- there's a large amount of implicit structure which is tedious to maintain
- sequence diagrams quickly get complex for processes with lots of actors and/or actions
- I can never remember all the conventions for representing concepts like alternation, loops and nesting
The language supports just about everything you might want - signal types, groups, nesting, notes, lifelines, etc. It outputs in images or as PDF - and it even has cool styles! Here's the idea:
loop 1000 times
Me->Visio: draw sequence diagram
Visio->Me: frustration
end
Me->Google: search for better way
Google->Me: find websequencediagram tool
Me->WebSequenceDiagram: draw sequence diagram
WebSequenceDiagram->Me: happiness!
produces

I've blogged about the appeal of specifying UML diagrams using code before. I'm not sure how much traction TextUML is getting - but it's hard to resist the appeal of a web interface, a simple language, and sexy ouput.
Now, if only someone would develop a force-directed web-based state diagram engine...
Note: there's some other alternatives to the websequencediagram tool - the author blogs about them here. The most interesting from my point of view is sdedit, which is open-source and Java-based. It's more powerful, but the language looks a mite complex. (Too bad there's no standard language for describing UML - maybe the Three Amigos should skip a siesta and whip one up.)
Monday, 4 May 2009
Voronoi Diagrams in JTS 1.11
As is well-known, the Voronoi diagram (or tesselation) is the dual of the Delaunay triangulation. So the new Delaunay Triangulation code in JTS has a natural extension to computing Voronoi diagrams. Thanks to the quad-edge data structure underlying the Delaunay algorithm this was relatively trivial to implement, after a few design issues were sorted out (such as:
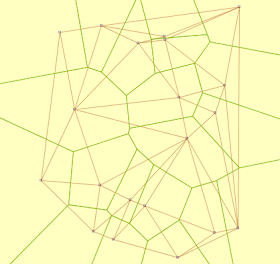


The JTS implementation scales very well - a Delaunay/Voronoi diagram of 1 million points computes in under 5 minutes. The one downside is memory usage. As usual, Java is quite memory-hungry - a 1 M point Delaunay takes around 700 MB. This seems excessive, even for Java. Hopefully some memory profiling may reveal that this can be reduced by some tuning of the class structures involved.
Even better, the Delaunay/Voronoi algorithm seems to be quite robust, even though no special attempt has been made to provide high-precision or otherwise robust implementations of some of the key predicates (inCircle and orientation). This may yet prove to be an issue for some inputs, but at this point it seems possible to claim that for non-pathological inputs the algorithms execute correctly.
- efficiently enumerating all vertices in the QuadEdge data structure which provides the basis for Delaunay computation
- computing the circumcentre of all Delaunay triangles in a consistent way
- clipping the generated Voronoi cell polygons to a reasonable bounding area)

Delaunay and Voronoi diagrams of 20 points (15 ms)

Voronoi diagram of 100 points (63 ms)

Voronoi diagram of 100,000 points (7.3 sec)
The JTS implementation scales very well - a Delaunay/Voronoi diagram of 1 million points computes in under 5 minutes. The one downside is memory usage. As usual, Java is quite memory-hungry - a 1 M point Delaunay takes around 700 MB. This seems excessive, even for Java. Hopefully some memory profiling may reveal that this can be reduced by some tuning of the class structures involved.
Even better, the Delaunay/Voronoi algorithm seems to be quite robust, even though no special attempt has been made to provide high-precision or otherwise robust implementations of some of the key predicates (inCircle and orientation). This may yet prove to be an issue for some inputs, but at this point it seems possible to claim that for non-pathological inputs the algorithms execute correctly.
Thursday, 30 April 2009
Delaunay Triangulation in JTS 1.11
The next version of JTS (1.11) will include an API for creating Delaunay triangulations and Conforming Delaunay triangulations. For a thorough explanation of the differences between Delaunay, Conforming Delaunay, and Constrained Delaunay, and why they are actually quite difficult to compute, see Jonathan Shewchuk's wonderful web site. [Side note - yet another B.C.-grown spatial dude - must be something in the water up here!]
This Delaunay implementation arose out of the work I did on automated watershed extraction using a system called WaterBuG a while back. It's taken a while to make its way into JTS because there's quite a bit of work involved in turning a codebase targeted at a very specific project into a clean, user-friendly API. Not to mention writing documentation...
But it's there now, and I'll be interested to see if it's of use to JTSer's. There seems to be a sudden surfeit of Delaunay and CDT Java libraries (see here, here, here, here and here), so I make no claims that the JTS one is best-of-breed. But hopefully having a decent implementation easily accessible and embedded in a general-purpose library will meet some needs. Also, my hope is that it will serve as the basis for further algorithms in JTS (such as the much-sought-after Concave Hull!).
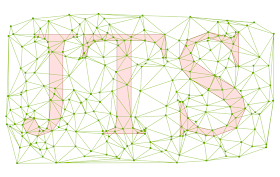
Here's some screenshots showing the triangulation API at work:
The input points and constraint segments:
 The Delaunay triangulation (notice that triangle edges cross some of the longer constraint edges):
The Delaunay triangulation (notice that triangle edges cross some of the longer constraint edges):
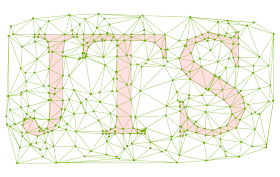
 A conforming Delaunay triangulation (the triangulation edges are now faithful to the constraint edges):
A conforming Delaunay triangulation (the triangulation edges are now faithful to the constraint edges):
This Delaunay implementation arose out of the work I did on automated watershed extraction using a system called WaterBuG a while back. It's taken a while to make its way into JTS because there's quite a bit of work involved in turning a codebase targeted at a very specific project into a clean, user-friendly API. Not to mention writing documentation...
But it's there now, and I'll be interested to see if it's of use to JTSer's. There seems to be a sudden surfeit of Delaunay and CDT Java libraries (see here, here, here, here and here), so I make no claims that the JTS one is best-of-breed. But hopefully having a decent implementation easily accessible and embedded in a general-purpose library will meet some needs. Also, my hope is that it will serve as the basis for further algorithms in JTS (such as the much-sought-after Concave Hull!).
Here's some screenshots showing the triangulation API at work:
The input points and constraint segments:
 The Delaunay triangulation (notice that triangle edges cross some of the longer constraint edges):
The Delaunay triangulation (notice that triangle edges cross some of the longer constraint edges): A conforming Delaunay triangulation (the triangulation edges are now faithful to the constraint edges):
A conforming Delaunay triangulation (the triangulation edges are now faithful to the constraint edges):
Wednesday, 4 March 2009
Web Monkeys with Laserbeams like JTS
...As they explain in this blog post about using JTS to simplify a polygonal coverage.
The really sweet thing is that not only do the Web Monkeys have laser beams, but also honkin' big computers as well. The post states that they use 7 GB of memory to process 41,000 polygons in a single batch (as is required for the simplification algorithm that they're using). I inquired and found out that they're using:
Niice... I've always wanted to experiment with large memory space for JTS processing, for things like large overlays, large TIN building, etc. So far I haven't had a machine large enough to let me try. But it sounds like 64-bit Java "just works", as expected. Another great reason for coding to a JVM - 64-bit memory space support with no recompilation!
The really sweet thing is that not only do the Web Monkeys have laser beams, but also honkin' big computers as well. The post states that they use 7 GB of memory to process 41,000 polygons in a single batch (as is required for the simplification algorithm that they're using). I inquired and found out that they're using:
java version "1.6.0_11"
Java(TM) SE Runtime Environment (build 1.6.0_11-b03)
Java HotSpot(TM) 64-Bit Server VM (build 11.0-b16, mixed mode)
Niice... I've always wanted to experiment with large memory space for JTS processing, for things like large overlays, large TIN building, etc. So far I haven't had a machine large enough to let me try. But it sounds like 64-bit Java "just works", as expected. Another great reason for coding to a JVM - 64-bit memory space support with no recompilation!
Tuesday, 3 March 2009
GM and VE side-by-side and head-to-head
Here's a nifty page which shows GM and VE side-by-side, with slaved navigation. It's quite handy for seeing differences in map rendering and imagery.
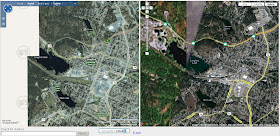
For my area of interest (Victoria B.C.) my 20-second appraisal is that they both have aspects of their rendering which are better than the other; and VE's imagery coverage is more limited than GM's (probably due to this deal).

For my area of interest (Victoria B.C.) my 20-second appraisal is that they both have aspects of their rendering which are better than the other; and VE's imagery coverage is more limited than GM's (probably due to this deal).
Tuesday, 13 January 2009
More on Database Thawing
I just saw this blog post in rebuttal to Martin Fowler's DatabaseThaw article. It's a typically well-thought out response from Typical Programmer. The short summary is that he rejects Fowler's criticism of using RDB's as the mechanism for application integration. (And don't dismiss him as simply a RDB bigot - he's not shy about nailing relational gurus, as in Relational Database Experts Jump The MapReduce Shark).
TP's arguments ring true to me, although in my experience it takes a very concientious DB shop to fully maintain the "encapsulation of data and operations" across many applications, many custodians, and many developers.
It would be great if Fowler's vision of the integration point being HTTP rather than SQL solved all our problems. Loose coupling is a wonderful thing to have. But so far I'm not seeing how this provides equivalent performance for all cases, and how it avoids the problem of data model mismatch.
TP's arguments ring true to me, although in my experience it takes a very concientious DB shop to fully maintain the "encapsulation of data and operations" across many applications, many custodians, and many developers.
It would be great if Fowler's vision of the integration point being HTTP rather than SQL solved all our problems. Loose coupling is a wonderful thing to have. But so far I'm not seeing how this provides equivalent performance for all cases, and how it avoids the problem of data model mismatch.
Friday, 9 January 2009
Is Global Database Warming happening?
Martin Fowler has a great blikiTM post on DatabaseThaw. The soundbite is something like "What happens after relational DBs?". He has some interesting links to things like Drizzle.
His opinon of relational DBs is that
This makes sense, but I think they also have offered the benefit of providing a fairly powerful, standard way of modelling and querying data. Over the lifetime of this technology this has fought off some powerful challengers, notably object-oriented data modelling. (Although perhaps this battle was only won by becoming more like the "loser"). The latest challenger is semantic data modelling (RDF, SPARQL, etc). Perhaps the world is ready to make this transition - although I'm not rushing to sell my Oracle stock.
He also makes a good point that the focus of integration is shifting from the DB to the Web. Hard to argue with this... the clouds are moving in!
His opinon of relational DBs is that
their dominance is due less to their role in data management than their role in integration
This makes sense, but I think they also have offered the benefit of providing a fairly powerful, standard way of modelling and querying data. Over the lifetime of this technology this has fought off some powerful challengers, notably object-oriented data modelling. (Although perhaps this battle was only won by becoming more like the "loser"). The latest challenger is semantic data modelling (RDF, SPARQL, etc). Perhaps the world is ready to make this transition - although I'm not rushing to sell my Oracle stock.
He also makes a good point that the focus of integration is shifting from the DB to the Web. Hard to argue with this... the clouds are moving in!
Thursday, 8 January 2009
Computing Geometric Similarity
The GEOS team is working on porting the JTS CascadedPolygonUnion algorithm. Reasonably enough they asked whether there were unit tests that they could use to check the correctness of their code. I was a bit dismayed to realize that in fact there weren't any unit tests for this class (although having used the code extensively I'm pretty confident that it's correct.)
So fine, some unit tests are needed. This should be easy, right? Just create or obtain some polygonal datasets, union them using both CascadedPolygonUnion (fast) and Geometry.union (slow), and compare the results.
But there's a catch (in geometric processing there usually is). Due to rounding effects, there's no guarantee that the results of the two algorithms will be vertex-by-vertex identical. Of course, they should be very, very similar... but how to check this?
In geometry processing it's usually much harder to test "similar" than it is to test "exact", and this case is no exception. In fact, there's many different tests that could be used, depending on how you want to define "similar". In the context of unit tests, similarity testing is essentially checking for discrepancies which might be introduced into a theoretically correct result. So the tests to use may depend on the operation(s) that are being performed, since different kinds of algorithms can produce different kinds of discrepancies. A further issue which needs to be considered is to detect gross differences which might result from catastrophic algorithm failure.
So now the task is to write a SimilarityValidator for geometries. For polygons there's various characteristics which can be compared:
 Hausdorff Distance between two polygons
Hausdorff Distance between two polygons
With this validator written and some test datasets run I can finally confirm that CascadedPolygonUnion actually works!
So fine, some unit tests are needed. This should be easy, right? Just create or obtain some polygonal datasets, union them using both CascadedPolygonUnion (fast) and Geometry.union (slow), and compare the results.
But there's a catch (in geometric processing there usually is). Due to rounding effects, there's no guarantee that the results of the two algorithms will be vertex-by-vertex identical. Of course, they should be very, very similar... but how to check this?
In geometry processing it's usually much harder to test "similar" than it is to test "exact", and this case is no exception. In fact, there's many different tests that could be used, depending on how you want to define "similar". In the context of unit tests, similarity testing is essentially checking for discrepancies which might be introduced into a theoretically correct result. So the tests to use may depend on the operation(s) that are being performed, since different kinds of algorithms can produce different kinds of discrepancies. A further issue which needs to be considered is to detect gross differences which might result from catastrophic algorithm failure.
So now the task is to write a SimilarityValidator for geometries. For polygons there's various characteristics which can be compared:
- A simple thing to do is to compare basic quantities like the area and perimeter length of the polygons. Paradoxically, these are good for detecting small discrepancies, but not for detecting gross ones (e.g. two identical rectangles which are offset by a large distance)
- One obvious thing to do is to compute the symmetricDifference of the polygons and inspect the area of the result. This has a couple of issues. One is what area tolerance to use? A more serious issue is that the symmetric difference operation is itself an approximation to an exact answer. This is especially true in situations where the inputs are very close - which is exactly the situation we are trying to check! So there may be a certain lack of confidence that this is detecting all discrepancies
- A more robust test is to compute the Hausdorff distance between the rings of the polygons. This allows expressing the tolerance in terms of distance, which is more intuitive. It's also fairly robust and easy to confirm the answer. There's a challenge in developing an efficient Hausdorff algorithm - but that's a topic for another blog post.
- Other tests might include comparing structural things like comparing the number of rings in the polygons.
 Hausdorff Distance between two polygons
Hausdorff Distance between two polygonsWith this validator written and some test datasets run I can finally confirm that CascadedPolygonUnion actually works!
Friday, 2 January 2009
JTS Version 1.10 released
I'm happy to announce that after a long gestation JTS 1.10 has been released. (This is my contribution to help fulfill James Fee's prediction 8^)
The package is available on SourceForge here.
There are numerous enhancements in this version. The highlights are:
The package is available on SourceForge here.
There are numerous enhancements in this version. The highlights are:
- Dramatic improvements to buffer performance, robustness and quality
- Moving the GML I/O classes into the core library, and provided more control over the emitted GML
- numerous bug fixes and performance improvements.
Functionality Improvements
- Added Geometry.reverse() method for all geometry types
- Added setSrsName, setNamespace, setCustomRootElements methods to GMLWriter
- Added Envelope.getArea method
- Added copy, copyCoord methods to CoordinateSequences
- Added area method to Envelope
- Added extractPoint(pt, offset) methods to LengthIndexedLine and LocationIndexedLine
- Added CoordinatePrecisionReducerFilter
- Added UnaryUnionOp(Collection, GeometryFactory) constructor to handle empty inputs more automatically
- Added DiscreteHausdorffDistance class
- Made LineMerger able to be called incrementally
- Added GeometricShapeFactory.createArcPolygon to create a polygonal arc
- Enhanced Geometry.buffer() to preserve SRID
Performance Improvements
- Improved performance for
EdgeList(by using a more efficient technique for detecting duplicate edges) - Improved performance for
ByteArrayInStream(by avoiding use of java.io.ByteArrayInputStream) - Unrolled intersection computation in HCoordinate to avoid object allocation
- Improved performance for buffering via better offset curve generation and simplification.
- Improved performance for IsValipOp by switching to use STRtree for nested hole checking
Bug Fixes
- Fixed Geometry.getClassSortIndex() to lazily initialize the sorted class list. This fixes a threading bug.
- Fixed RectangleContains to return correct result for points on the boundary of the rectangle
- Fixed error in com.vividsolutions.jts.simplify.LineSegmentIndex which caused polygons simplified using TopologyPreservingSimplifier to be invalid in certain situations
- Fixed error in DouglasPeuckerSimplifier which caused empty polygons to be returned when they contained a very small hole
- Fixed PackedCoordinateSequence to return NaN for null ordinate values
- Fixed Geometry.centroid() (CentroidArea) so that it handles degenerate (zero-area) polygons
- Fixed Geometry.buffer() (OffsetCurveBuilder) so that it handles JOIN_MITRE cases with nearly collinear lines correctly
- Fixed GeometryFactory.toGeometry(Envelope) to return a CW polygon
- Fixed UnaryUnionOp to correctly handle heterogeneous inputs with P/L/A components
- Fixed UnaryUnionOp to accept LINEARRINGs
- Fixed CentroidArea to handle zero-area polygons correctly
- Fixed WKBWriter to always output 3D when requested, and to handle 2D PackedCoordinateSequences correctly in this case
- Fixed NodedSegmentString to handle zero-length line segments correctly (via safeOctant)
- Cleaned up code to remove unneeded CGAlgorithms objects
- Fixed GeometricShapeFactory.createArc to ensure arc has requested number of vertices
API Changes
- Moved GML I/O classes into core JTS codebase
- Changed GMLWriter to not write the srsName attribute by default
- In DistanceOp switched to using nearestPoints method names
- Exposed STRtree.getRoot() method
JTS TestBuilder
UI Improvements
- Added ability to read GML from input panel
- Added GML output to View dialog
- Added file drag'n'drop to Geometry Input text areas
- Add display of computation time
- Added Stats panel
- Added Scalar functions panel, with extensible function list
- Added Save as PNG...
JTS TestRunner
Functionality Improvements
- Added -testCaseIndex command-line option