
Friday, 15 November 2013
Maslow's Hierarchy in the 21st Century
Been a while since I posted, so posting some humour seems like a good start to getting back on track...
Wednesday, 12 June 2013
How to get OpenLayers WMSGetFeatureInfo to emit GeoServer CQL Filters for multiple layers
OpenLayers provides the useful WMSGetFeatureInfo control. It's designed to work with the standard WMS GetFeatureInfo request. As per the standard, the control supports querying multiple layers via setting the layers property.
It's often necessary to define client-side filters for WMS layers, to display only a subset of the layer data in the backing feature type. Usually the filters need to be defined dynamically, based on the application context. When using GeoServer as the web mapping engine a convenient (but non-standard) way of doing this is to use the CQL_FILTER WMS parameter. (One might reasonably ask why there isn't an equally simple way to do this in the WMS standard itself, but that's another story). In OpenLayers this parameter can be added dynamically to a layer via the mergeNewParams method:
Naturally it is necessary to have the GetFeatureInfo control respect the layer filters as well. This is straightforward in the case of a single layer. The GeoServer CQL_FILTER parameter can be supplied using the vendorParams property on the WMSGetFeatureInfo control:
Since the CQL_FILTER parameter supports a list of filters, it's also straightforward to filter multiple layers as long as the list of layers queried is static:
But WMSGetFeatureInfo also provides the useful ability to query only visible layers (via the queryVisible property). This makes things much trickier, since the list of filter expressions must match the list of layers provided in the QUERY_LAYERS parameter. There's no built-in way of doing this in OpenLayers itself (not surprisingly, since the CQL_FILTER parameter syntax is specific to GeoServer only).
One way to do this is to build the CQL_FILTER parameter value dynamically uisng the CQL_FILTERs defined for the visible layers. This can be done when the control is invoked, via hooking the beforegetfeatureinfo event.
Here's a code snippet to do this:
Although climbing up the OpenLayers learning curve often feels like a big struggle, it's important to recognize the very wide set of requirements that the library is trying to address. Due to the nature of spatial data, user interfaces and protocols dealing with it are inherently complex. The more I work with OpenLayers, the more appreciation I have for the fine balance between simplicity and flexibility the designers have achieved. (And if that sounds like I do not subscribe to the "Spatial is not special" canard, you're hearing me right!).
It's often necessary to define client-side filters for WMS layers, to display only a subset of the layer data in the backing feature type. Usually the filters need to be defined dynamically, based on the application context. When using GeoServer as the web mapping engine a convenient (but non-standard) way of doing this is to use the CQL_FILTER WMS parameter. (One might reasonably ask why there isn't an equally simple way to do this in the WMS standard itself, but that's another story). In OpenLayers this parameter can be added dynamically to a layer via the mergeNewParams method:
lyr.mergeNewParams({'CQL_FILTER': "filter expression" });
Naturally it is necessary to have the GetFeatureInfo control respect the layer filters as well. This is straightforward in the case of a single layer. The GeoServer CQL_FILTER parameter can be supplied using the vendorParams property on the WMSGetFeatureInfo control:
infoControl.vendorParams = { 'CQL_FILTER': 'filter expression'};
Since the CQL_FILTER parameter supports a list of filters, it's also straightforward to filter multiple layers as long as the list of layers queried is static:
infoControl.vendorParams = { 'CQL_FILTER': 'filt-1; filt-2; filt-3'};
But WMSGetFeatureInfo also provides the useful ability to query only visible layers (via the queryVisible property). This makes things much trickier, since the list of filter expressions must match the list of layers provided in the QUERY_LAYERS parameter. There's no built-in way of doing this in OpenLayers itself (not surprisingly, since the CQL_FILTER parameter syntax is specific to GeoServer only).
One way to do this is to build the CQL_FILTER parameter value dynamically uisng the CQL_FILTERs defined for the visible layers. This can be done when the control is invoked, via hooking the beforegetfeatureinfo event.
Here's a code snippet to do this:
var infoControl;
function initInfoControl()
{
infoControl = new OpenLayers.Control.WMSGetFeatureInfo({
url: wms_url,
title: 'Identify features by clicking',
layers: [
layers....
],
queryVisible: true,
maxFeatures: 3,
infoFormat: 'application/vnd.ogc.gml'
});
infoControl.events.register(
"beforegetfeatureinfo", null, onBeforeGetFeatureInfo);
infoControl.events.register
("getfeatureinfo", null, onGetFeatureInfo);
map.addControl(infoControl);
infoControl.activate();
}
function onBeforeGetFeatureInfo(event)
{
// build CQL_FILTER param list from active info layer CQL_FILTER params
var layers = infoControl.findLayers();
var filter = "";
for (var i = 0, len = layers.length; i < len; i++) {
if (i > 0) filter += ";";
var lyrCQL = layers[i].params.CQL_FILTER
if (lyrCQL != null) {
filter += lyrCQL;
}
}
infoControl.vendorParams = { 'CQL_FILTER': filter };
}
Although climbing up the OpenLayers learning curve often feels like a big struggle, it's important to recognize the very wide set of requirements that the library is trying to address. Due to the nature of spatial data, user interfaces and protocols dealing with it are inherently complex. The more I work with OpenLayers, the more appreciation I have for the fine balance between simplicity and flexibility the designers have achieved. (And if that sounds like I do not subscribe to the "Spatial is not special" canard, you're hearing me right!).
Wednesday, 29 May 2013
Flight Paths in JEQL Redux
The intertubes are buzzing about a flight path visualization done by Michael Markieta. This is based on the same OpenFlights dataset that I used a couple of years ago as a demonstration of JEQL processing and visualization capabilities.
Markieta's blog post outlines his workflow using ArcGIS. It's a bit cumbersome - apart from having to jump through hoops to read the data from the original DAT files, apparently the dataset has to be split into six parts to be able to process it. (For a measly 58K rows?!)
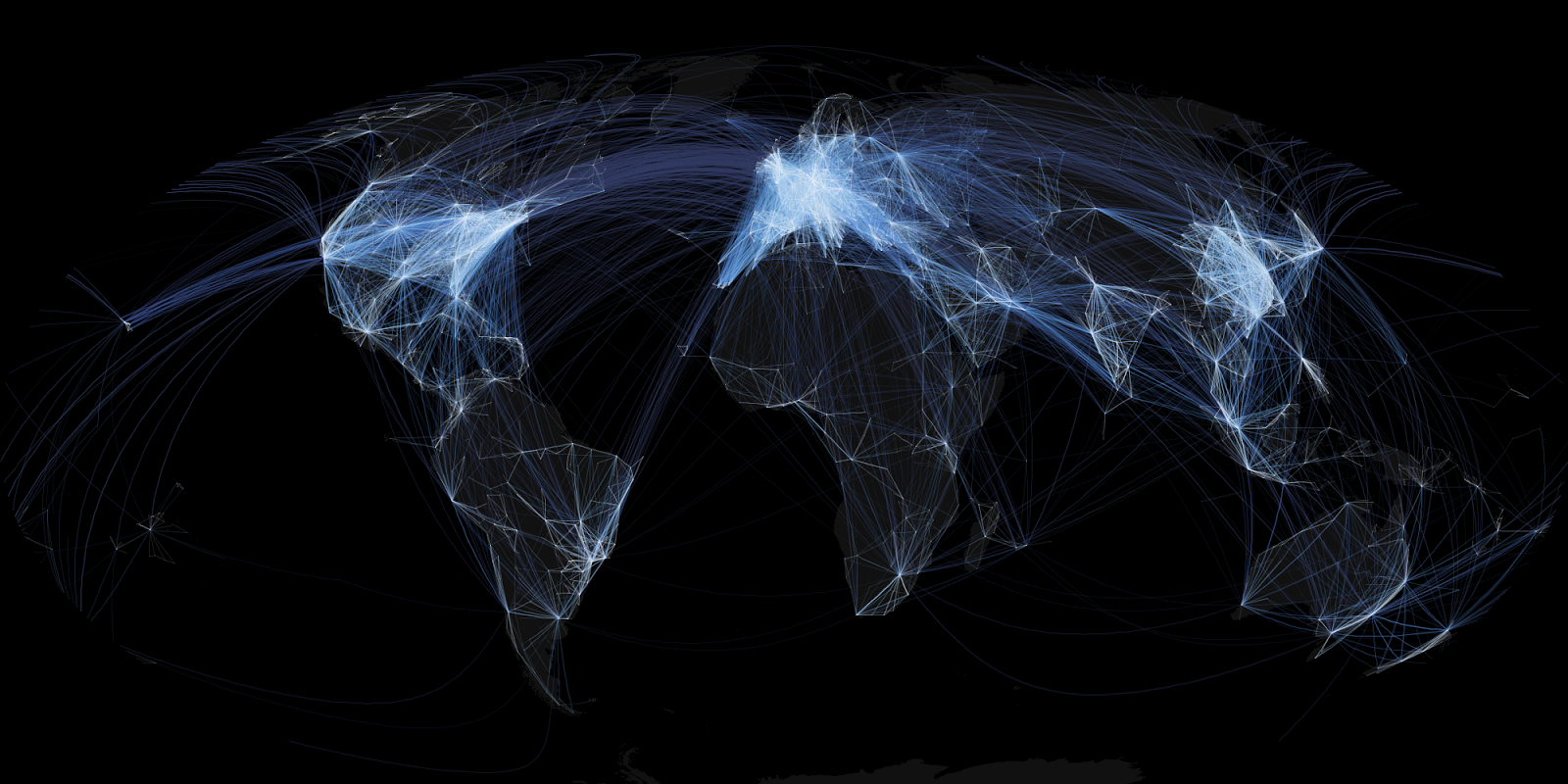
No details are provided about styling, which is the key part of the exercise. The images apparently use alpha blending to show flight density. Also, the coordinate system seems to be more curvaceous than the squaresville Plate Carree I used (so much more haute couture than saying Lat/Long). Both of these are easy to do in JEQL. Here's some samples of the improved output, using the alpha channel and a Mollwiede projection.


And here's the entire image, in glorious hi-res suitable for framing:

Markieta's blog post outlines his workflow using ArcGIS. It's a bit cumbersome - apart from having to jump through hoops to read the data from the original DAT files, apparently the dataset has to be split into six parts to be able to process it. (For a measly 58K rows?!)
No details are provided about styling, which is the key part of the exercise. The images apparently use alpha blending to show flight density. Also, the coordinate system seems to be more curvaceous than the squaresville Plate Carree I used (so much more haute couture than saying Lat/Long). Both of these are easy to do in JEQL. Here's some samples of the improved output, using the alpha channel and a Mollwiede projection.

Europe
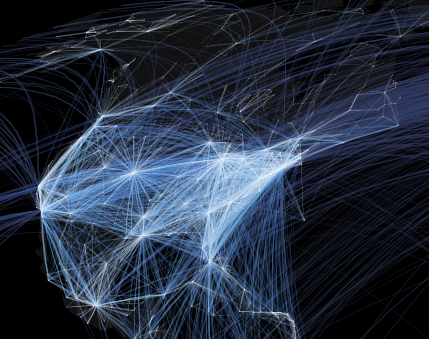
North America
And here's the entire image, in glorious hi-res suitable for framing:
Monday, 13 May 2013
Beautiful cartography using OpenJUMP
An OpenJUMP user just posted some really nice cartographic maps made using a combination of OpenJUMP, Inkscape, GRASS, and GIMP.



{kind=link}

{kind=link}

He gives OJ the following glowing endorsement:
I find Open JUMP to be the most vector-friendly open source GIS software. The preparation of the datasets (rivers, lakes, sea, roads, borders) was really [a] piece of cake...
It's great to see the small but dedicated OpenJUMP community steadily adding new features and improving the software quality. 10 years after it was launched, OpenJUMP continues to be the "Little Open-Source GIS that Can".
Thursday, 14 March 2013
10 Step Program for Developers
Andrew Oliver lays out the 10 Step Program for developers. Here's his points:
- Blog
- Go open source
- Not six months, not 10 years
- Eye on the new stuff, hands on the practical
- Write your own documentation
- Brevity is the soul
- Wow the crowd
- Be realistic
- Solve the hard stuff, know the tools (hmm.. isn't that two points?)
- Practice humility
This blog post is my practice of points 1 and 6. And also one of my own:
11. Copy the work of other smart people
Tuesday, 12 February 2013
The subversiveness of Open Source
It's no longer novel to observe that Open Source is, if not the dominant software paradigm of the era, at least one of the most significant innovations
in the history of software practice. Recently it struck me how downright bizarre the Open Source paradigm really is. I can't think of another field of human endeavour where the fundamental paradigm mandates giving away the product of one's labour. Consider a few sweepingly-generalized examples:
Long live the anarcho-syndicalist commune of Open Source Software craftsmen!
- Business - Fugedaboudit! It's all about the money. Apart from the Diggers of 60's Haight-Ashbury notoriety there aren't too many examples of businesses whose model consists of giving away their stock.
- Arts - Hah! Obviously the big media companies are doing everything they can to squeeze money out of artistic endeavour. But even among the less mercantile stakeholders the main discussion is about how artists can be compensated for their creations. No-one seriously advocates that artists give away all their work for free.
- Sport - Don't get me started on the gross discrepancy between compensation and value in professional sport. And at the amateur level, sponsorship and funding organizations are recognized to be essential to promoting the continued generation of sporting "product". (Wouldn't it be great if there was a similar system of sponsorship for software developers?)
- Science - You might think this would be the exception that proves the rule. After all, sharing research results is a revered principle of scientific progress. The domain relies on publishing information openly to an even greater extent than in software development. But in my (admittedly limited) experience many scientists are actually quite protective of their intellectual property, since their livelihood depends in a direct way on amassing it and monetizing how it is dispensed. And it's well known that academic institutions pay very close attention to licensing the IP generated by them (or their employees).
Long live the anarcho-syndicalist commune of Open Source Software craftsmen!
Wednesday, 6 February 2013
JTS Union VS ArcGIS Dissolve
Ragnvald Larsen has an interesting post on ways to mitigate the poor performance and stabilty of Dissolve computations in ArcGIS. Dissolve is the Arc term for the geometric union of a collection of polygons (possibly grouped by attribute, although that capability was not used in this case).
Ragnvald's dataset consisted of a 15 MB shapefile containing about 7000 overlapping polygons. Here's what the data looks like:

He found that using the ArcGIS Dissolve method took about 150 sec to process the dataset. In an effort to reduce this time, he experimented with partitioning the dataset and doing the union in batches. After a (presumably lengthy) series of experiments to find the optimal batch size, he was able to get the time down to 25 sec using a batch size of 110 features.
Improving union performance by partioning the input is the basic idea behind the Cascaded Union function in JTS (which I blogged about back in 2007). Cascaded Union uses a spatial index to automatically optimize the partitioning. Ragnvald doesn't mention whether he used a spatial index, but I suspect this might be quite time-consuming to code in ArcPy.
I thought it would be interesting to compare the performance of the JTS algorithm to the ArcGIS one. To do this I used JEQL, which provides an easy high-level way to read the data and invoke the JTS Cascaded Union. The entire process can be expressed as a very simple JEQL script:
geomUnionMem is a JEQL spatial aggregate function which is implemented using the JTS Cascaded Union algorithm. (Although not needed in this case, note that the more general Dissolve use case of unioning groups of features by their attributes can easily be achieved by using the standard SQL GROUP BY clause.)
Running this on a (late-model) PC workstation produced a timing of about 1.5 sec!
Here's the output union:

Ragnvald's dataset consisted of a 15 MB shapefile containing about 7000 overlapping polygons. Here's what the data looks like:
He found that using the ArcGIS Dissolve method took about 150 sec to process the dataset. In an effort to reduce this time, he experimented with partitioning the dataset and doing the union in batches. After a (presumably lengthy) series of experiments to find the optimal batch size, he was able to get the time down to 25 sec using a batch size of 110 features.
Improving union performance by partioning the input is the basic idea behind the Cascaded Union function in JTS (which I blogged about back in 2007). Cascaded Union uses a spatial index to automatically optimize the partitioning. Ragnvald doesn't mention whether he used a spatial index, but I suspect this might be quite time-consuming to code in ArcPy.
I thought it would be interesting to compare the performance of the JTS algorithm to the ArcGIS one. To do this I used JEQL, which provides an easy high-level way to read the data and invoke the JTS Cascaded Union. The entire process can be expressed as a very simple JEQL script:
ShapefileReader t file: "agder/agder_buffer.shp";
t = select geomUnionMem(GEOMETRY) g from t;
ShapefileWriter t file: "result.shp";
geomUnionMem is a JEQL spatial aggregate function which is implemented using the JTS Cascaded Union algorithm. (Although not needed in this case, note that the more general Dissolve use case of unioning groups of features by their attributes can easily be achieved by using the standard SQL GROUP BY clause.)
Running this on a (late-model) PC workstation produced a timing of about 1.5 sec!
Here's the output union:
Thursday, 3 January 2013
Functional Programming Whinging
Tim Bray thinks Uncle Bob Martin's post on Functional Programming Basics is the cat's pyjamas.
Meh. "Basics" is the key word in that title - the article is pretty light and fluffy. Fine if you don't know squat about FP, but it's also accompanied by a whole lot of starry-eyed razzle-dazzle which isn't really justified by the content (and note that I'm not saying it's wrong, just not substantiated).
To be fair, TB does have a few gripes. Here's a few more:
Meh. "Basics" is the key word in that title - the article is pretty light and fluffy. Fine if you don't know squat about FP, but it's also accompanied by a whole lot of starry-eyed razzle-dazzle which isn't really justified by the content (and note that I'm not saying it's wrong, just not substantiated).
To be fair, TB does have a few gripes. Here's a few more:
- The example used to show how FP wonderfully avoids variables and side-effects is that hoary old one of computing squares of integers. (I mean really hoary - this was the first program I ever wrote, in WATFIV. And I at least had cool line printer output!) How about using something that's a bit more representative of an actual computational problem? Like say, red-black trees - with deletion!
- As TB points out, the people who really need to make algorithms run fast across 64 cores are a small percentage of current coders. For everyone else, scale-out is a more mundane but pressing problem. And it's not clear to me whether FP will make that easier.
- As someone who spends his leisure hours trying to make spatial algorithms more performant, I'm suspicious of anything that promises to automagically make code go faster across multiple cores. In spatial most interesting problems are not "pleasantly parallel", and many of them are memory-bound as well as being compute-bound. So advances in performance would seem depend on better algorithms, not a different choice of language.
Back in the day I was pretty keen on FP languages - but I realized after being exposed to Smalltalk and later Java, a lot of their appeal was due to their (necessary) provision of automatic memory management (which was painfully lacking in the "mainstream" languages such as FORTRAN, Pascal, C - oh, and even C++).
But I'm not trying to prove a negative here. Certainly the FP features of no side-effects and lazy evaluation would seem to offer a lot of benefit for the right class of problems. And FP or FP-ish languages are more mainstream than ever before. So perhaps they really will become the mainstream language paradigm. I just hope I don't have to be coding using layers of inconveniently situated parentheses.
Lead, the criminal element
I've heard before about the postulated link between atmospheric lead levels (courtesy of the leaded gasoline used through the middle decades of the 20th century) and crime levels. This Mother Jones article America's Real Criminal Element: Lead is the best explanation I've seen so far (and has links to the original papers). It really sounds like this hypothesis is fully confirmed - and the best thing about this story is that it has a happy ending. (Unless you're trying to get elected as mayor - or Prime Minister - on a tough-on-crime platform).

There is a nice geospatial connection here. As with many epidemiological issues, spatial locality is an important aspect of the analyses that lead (ahem) to the conclusion. The article is chock-full of references to the spatial nature of the problem, such as:

There is a nice geospatial connection here. As with many epidemiological issues, spatial locality is an important aspect of the analyses that lead (ahem) to the conclusion. The article is chock-full of references to the spatial nature of the problem, such as:
We now have studies at the international level, the national level, the state level, the city level, and even the individual leveland my favourite:
a good rule of thumb for categorizing epidemics: If it spreads along lines of communication, he says, the cause is information. Think Bieber Fever. If it travels along major transportation routes, the cause is microbial. Think influenza. If it spreads out like a fan, the cause is an insect. Think malaria. But if it's everywhere, all at once—as both the rise of crime in the '60s and '70s and the fall of crime in the '90s seemed to be—the cause is a molecule.
Wednesday, 2 January 2013
2012 Year in Review - Blog Roundup
A look back at 2012 from a software technology perspective by some of my favourite blogs:
- Inspired By Actual Events - a wide-reaching roundup. I found the Java and friends links especially interesting, since the Java/JVM world is so big now it's hard to keep up with and distill the really significant events.
- Interoperability Happens (Ted Nedward) - As usual, opinionated and insightful commentary on enterprise software technology from a hard-core developer perspective.
- Tim Anderson - A strong focus on Microsoft, but also fairly even-handed assessment of the rest of the "A"-team (Apple, Android/Google, and Amazon). (And a not-very-optimistic mention of the "B" team - BB/RIM). I always appreciate Tim Anderson's reading of the internal and external tea-leaves of MS technology. It's always fascinating to see the elephant trying to jump, in a schadenfreudal sort of way.
- Tim Bray - Not really a roundup, and not all that tech-focussed, but always a good read.