A great article on the emerging SMAQ stack for big data.
I wonder if PIG does spatial?
Tuesday, 28 December 2010
Monday, 27 December 2010
Diving deep into Computational Geometry
For a deep dive into the bracing waters of cutting-edge computational geometry, check out the online proceedings of the Canadian Conference of Computational Geometry.
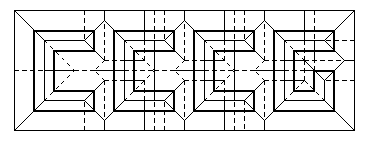
Do NOT expect to see these algorithms appear in JTS anytime soon!
Do NOT expect to see these algorithms appear in JTS anytime soon!
Sunday, 26 December 2010
Visualizing geodetic information with JEQL
The geo-blogosphere has been buzzing about the global Facebook friends visualization. This was done by Paul Butler using an R script and some clever techniques for working with geodetic data.

This kind of lightweight spatial analysis and visualization is squarely in the target zone for JEQL, so I thought I'd try something similar.
Of course I don't have access to the Facebook friends dataset, so I needed some other suitable dataset of global-scale links. An obvious candidate is airline routes. Luckily there is an excellent open data repository called OpenFlights. It has datasets which are tables of airport locations and air routes between airports:
airports.dat:
routes.dat:
The first step is to prepare a suitable dataset for rendering. To get a table of FROM/TO locations, the routes table needs to be joined to the airport table. This is trivial to do in JEQL. After a bit of cleanup (such as removing missing data and duplicate routes), the final result is a dataset of links between airport locations using Lat/Long coordinates:
As Paul found, a few other steps are needed to produce a visually appealing map:
The rendering is done using the following JEQL script:
That's about 40 lines of code, with only 9 statements. Not a bad LOC score... Of course the heavy lifting of handling geodetic data is done by Java functions, but that's part of the point. JEQL makes it easy to link to Java code, since that's a more appropriate technology for creating performant, resusable code.
Here's the final output:
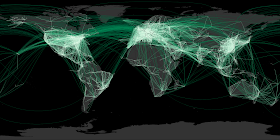
The continent outlines aren't revealed as crisply as the Facebook friends map. That's because friend links tend to be more spatially coherent than airline routes (unless your acquaintances all have private jets). But it certainly shows where the world hotspots are for air traffic. Boy, those Europeans love to fly!
Next up: the KML version...
This kind of lightweight spatial analysis and visualization is squarely in the target zone for JEQL, so I thought I'd try something similar.
Of course I don't have access to the Facebook friends dataset, so I needed some other suitable dataset of global-scale links. An obvious candidate is airline routes. Luckily there is an excellent open data repository called OpenFlights. It has datasets which are tables of airport locations and air routes between airports:
airports.dat:
1,"Goroka","Goroka","Papua New Guinea","GKA","AYGA",-6.081689,145.391881,5282,10,"U"
2,"Madang","Madang","Papua New Guinea","MAG","AYMD",-5.207083,145.7887,20,10,"U"
3,"Mount Hagen","Mount Hagen","Papua New Guinea","HGU","AYMH",-5.826789,144.295861,5388,10,"U"
...
routes.dat:
0B,1542,AGP,1230,BBU,1650,,0,738
0B,1542,ARW,1647,BBU,1650,,0,340
0B,1542,BBU,1650,AGP,1230,,0,738
...
The first step is to prepare a suitable dataset for rendering. To get a table of FROM/TO locations, the routes table needs to be joined to the airport table. This is trivial to do in JEQL. After a bit of cleanup (such as removing missing data and duplicate routes), the final result is a dataset of links between airport locations using Lat/Long coordinates:
28,"Bagotville","Canada",48.330555,-70.996391,146,"Montreal","Canada",45.470556,-73.740833
29,"Baker Lake","Canada",64.298889,-96.077778,132,"Rankin Inlet","Canada",62.81139,-92.115833
30,"Campbell River","Canada",49.950832,-125.270833,119,"Comox","Canada",49.710833,-124.886667
30,"Campbell River","Canada",49.950832,-125.270833,156,"Vancouver","Canada",49.193889,-123.184444
...
As Paul found, a few other steps are needed to produce a visually appealing map:
- Densify the route links to produce approximations to great-circle arcs
- Break the arcs at the International Date Line to allow them to render correctly
- Colour-theme the routes from longest to shortest using lighter colours for shorter routes
- Render the lines with longer ones further back in the Z-order
The rendering is done using the following JEQL script:
CSVReader troute hasColNames: file: "routeLine2.csv";
trte = select fromCity, toCity,
Val.toDouble(fromLon) fromLon, Val.toDouble(fromLat) fromLat,
Val.toDouble(toLon) toLon, Val.toDouble(toLat) toLat
from troute;
tlines = select fromCity, toCity, line, len
with {
line = Geodetic.split180(Geodetic.arc(fromLon, fromLat, toLon, toLat, 2));
len = Geom.length(line);
}
from trte order by len desc;
tplot = select line,
Color.interpolate("f0fff0", "00c077", "004020", len / 200.0 ) lineColor,
0.4 lineWidth
from tlines;
//----- Plot world landmasses for context
ShapefileReader tworld file: "world.shp";
tworldLine = select GEOMETRY, "22222277" lineColor from tworld;
tworldFill = select GEOMETRY, "333333" fillColor from tworld;
width = 2000;
Plot width: width height: width / 2
extent: LINESTRING(-180 -90, 180 90)
data: tworldFill
data: tplot
data: tworldLine
file: "routes.png";
That's about 40 lines of code, with only 9 statements. Not a bad LOC score... Of course the heavy lifting of handling geodetic data is done by Java functions, but that's part of the point. JEQL makes it easy to link to Java code, since that's a more appropriate technology for creating performant, resusable code.
Here's the final output:

The continent outlines aren't revealed as crisply as the Facebook friends map. That's because friend links tend to be more spatially coherent than airline routes (unless your acquaintances all have private jets). But it certainly shows where the world hotspots are for air traffic. Boy, those Europeans love to fly!
Next up: the KML version...
Monday, 15 November 2010
Single-Sided Buffers in JTS
Due to popular demand I have added the capability to generate Single-Sided Buffers to JTS.
A single-sided buffer is the polygon formed by connecting a LineString to an offset curve generated on one side of the line.
 Input Line
Input Line
 Single-Sided Buffer (width = 30)
Single-Sided Buffer (width = 30)
Naturally either side can be specified, by choosing an appropriate sign for the offset distance (positive for the right side, negative for the left).
 Single-Sided Buffer (width = -30)
Single-Sided Buffer (width = -30)
At the moment there's a bit of a limitation, in that input linework with very narrow concave angles (relative to the buffer distance) create undesirable artifacts in the generated polygon. I'm hoping that some further thinking will come up with a way to avoid this, at least in most normal cases.
This functionality is accessed by setting an appropriate flag in the BufferParameters structure:
Currently this code is in SVN. It will be released in JTS 1.12 (which will hopefully be shippingbefore year-end in Q2 2011).
A single-sided buffer is the polygon formed by connecting a LineString to an offset curve generated on one side of the line.
 Input Line
Input Line Single-Sided Buffer (width = 30)
Single-Sided Buffer (width = 30)Naturally either side can be specified, by choosing an appropriate sign for the offset distance (positive for the right side, negative for the left).
 Single-Sided Buffer (width = -30)
Single-Sided Buffer (width = -30)At the moment there's a bit of a limitation, in that input linework with very narrow concave angles (relative to the buffer distance) create undesirable artifacts in the generated polygon. I'm hoping that some further thinking will come up with a way to avoid this, at least in most normal cases.
This functionality is accessed by setting an appropriate flag in the BufferParameters structure:
BufferParameters bufParams = new BufferParameters();
bufParams.setSingleSided(true);
return BufferOp.bufferOp(geom, distance, bufParams);
Currently this code is in SVN. It will be released in JTS 1.12 (which will hopefully be shipping
Thursday, 19 August 2010
Magnifying Topology using JTS
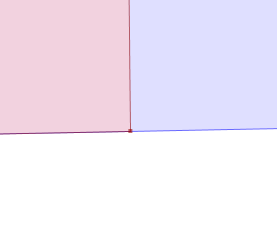
An issue that comes up all the time in the JTS world is how to visualize the topology of geometries which have very close vertices and segments. For example, a question was recently posted on the PostGIS list about why in the situation shown below the spatial relationship predicate BLUE.contains(RED) evaluates to FALSE
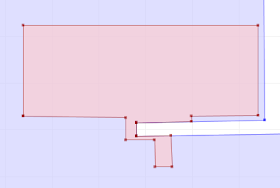
At first glance it looks like the red polygon follows the boundary of the blue one exactly, which would result in BLUE.contains(RED) = TRUE. The immediate suspicion is that one of the apparently collinear points is actually in the exterior of the blue polygon. But which one? And how can this be confirmed visually?
Now it so happens that the rightmost vertex of the red polygon, which appears to be on the boundary of the blue polygon, is in fact in the its exterior - thus explaing why contains = FALSE. But it's so close to the boundary segment that no matter how far you zoom in, you can't see that this is the case. And it's certainly not obvious where to go looking for this error in the first place.
Back in the Dark Ages
The usual way to inspect these kinds of cases is is to tediously zoom in on each vertex. But this loses the visual context of the situation. And in very close cases it simply doesn't work, because the zoom factor is so great that the Swing graphics API is unable to display the scene correctly.
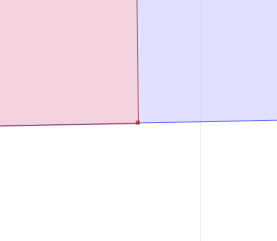
 Another alternative is a painstaking manual inspection of the coordinates of each vertex and segment (which by the way is straightforward in the TestBuilder and OpenJUMP, but can be difficult in other tools). But it's hard to convert the coordinate numbers into a mental image of the situation. And it's essentially impossible to do mentally if a vertex is near a non-rectilinear (slanted) line - in this case it's necessary to evaluate a complex mathematical algorithm to to determine the relative orientation of the vertex and line.
Another alternative is a painstaking manual inspection of the coordinates of each vertex and segment (which by the way is straightforward in the TestBuilder and OpenJUMP, but can be difficult in other tools). But it's hard to convert the coordinate numbers into a mental image of the situation. And it's essentially impossible to do mentally if a vertex is near a non-rectilinear (slanted) line - in this case it's necessary to evaluate a complex mathematical algorithm to to determine the relative orientation of the vertex and line.
Into the 21st Century!
This limitation has bugged me for a long time, ever since JTS and the JCS Conflation Suite were being developed. And it keeps coming up as a question, since this kind of situation occurs a lot when overlaying polygons. Cutting new vertices into line segments almost always causes them to be non-coincident with the original segment, but with very, very small discrepancies.
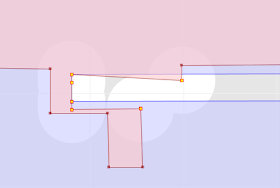
So a while back I started to think about a tool that would somehow make subtle topological situations visible at convenient zoom levels. The idea has been gathering dust on the lab bench for years, but I've finally had a chance to implement it. It's now a feature in the JTS TestBuilder called Magnify Topology. Enabling it on changes the geometry view to provide easy and effective visualization of small topological differences.
Key aspects of Magnify Topology behaviour are:
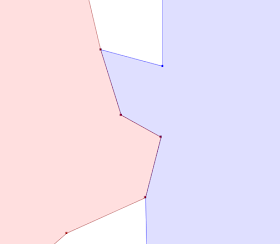
Now it's obvious where the red polygon violates the contains relationship! In addition, you can see that there are some very close vertices in the red polygon, that some of them are truly collinear with the blue boundary, and that the lower right red vertex is actually in the interior of the blue polygon.
Here's some more examples, showing actual and magnified views:
Example 1
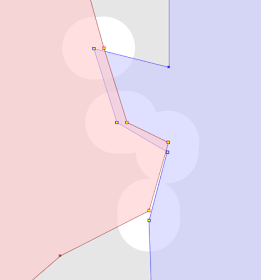
Example 2
Note the truly coincident vertex along the boundary, which remains unchanged in the magnified view.

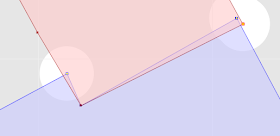
Example 3
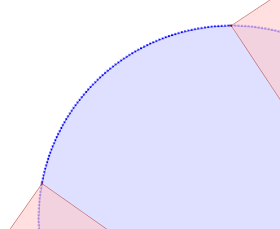
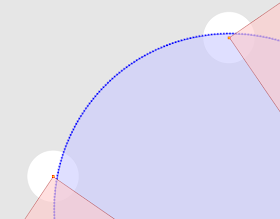
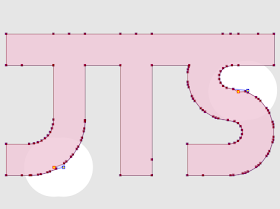
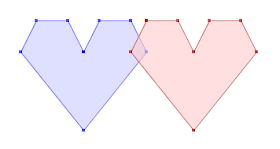
Magnify Topology can also be used to detect and visualized differences between similar geometries (sort of like a visual geometric diff) Here's a contrived example, showing two copies of a JTS logo, in which one copy has two tiny discrepancies (in the 15th decimal place!):
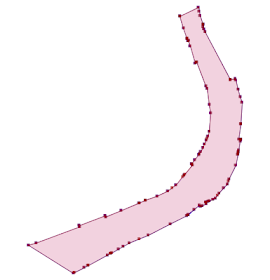
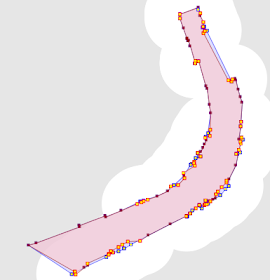
Here's a more realistic real-world example:
This feature will be released in the next version of JTS. In the meantime it's available in the JTS SVN.

At first glance it looks like the red polygon follows the boundary of the blue one exactly, which would result in BLUE.contains(RED) = TRUE. The immediate suspicion is that one of the apparently collinear points is actually in the exterior of the blue polygon. But which one? And how can this be confirmed visually?
Now it so happens that the rightmost vertex of the red polygon, which appears to be on the boundary of the blue polygon, is in fact in the its exterior - thus explaing why contains = FALSE. But it's so close to the boundary segment that no matter how far you zoom in, you can't see that this is the case. And it's certainly not obvious where to go looking for this error in the first place.
Back in the Dark Ages
The usual way to inspect these kinds of cases is is to tediously zoom in on each vertex. But this loses the visual context of the situation. And in very close cases it simply doesn't work, because the zoom factor is so great that the Swing graphics API is unable to display the scene correctly.
Zoomed in...

Zoomed further in...

Zoomed way in - FAIL!
 Another alternative is a painstaking manual inspection of the coordinates of each vertex and segment (which by the way is straightforward in the TestBuilder and OpenJUMP, but can be difficult in other tools). But it's hard to convert the coordinate numbers into a mental image of the situation. And it's essentially impossible to do mentally if a vertex is near a non-rectilinear (slanted) line - in this case it's necessary to evaluate a complex mathematical algorithm to to determine the relative orientation of the vertex and line.
Another alternative is a painstaking manual inspection of the coordinates of each vertex and segment (which by the way is straightforward in the TestBuilder and OpenJUMP, but can be difficult in other tools). But it's hard to convert the coordinate numbers into a mental image of the situation. And it's essentially impossible to do mentally if a vertex is near a non-rectilinear (slanted) line - in this case it's necessary to evaluate a complex mathematical algorithm to to determine the relative orientation of the vertex and line.Into the 21st Century!
This limitation has bugged me for a long time, ever since JTS and the JCS Conflation Suite were being developed. And it keeps coming up as a question, since this kind of situation occurs a lot when overlaying polygons. Cutting new vertices into line segments almost always causes them to be non-coincident with the original segment, but with very, very small discrepancies.
So a while back I started to think about a tool that would somehow make subtle topological situations visible at convenient zoom levels. The idea has been gathering dust on the lab bench for years, but I've finally had a chance to implement it. It's now a feature in the JTS TestBuilder called Magnify Topology. Enabling it on changes the geometry view to provide easy and effective visualization of small topological differences.

Key aspects of Magnify Topology behaviour are:
- Vertex displacement is done in a way that preserves the original topology (e.g. if a vertex is on the right side of a line it will stay on the right)
- Vertices which are truly coincident or collinear remain unchanged in the magnified view.
- It's easy and quick to toggle Magnify Topology on and off to compare the actual and magnified views.

Now it's obvious where the red polygon violates the contains relationship! In addition, you can see that there are some very close vertices in the red polygon, that some of them are truly collinear with the blue boundary, and that the lower right red vertex is actually in the interior of the blue polygon.
Here's some more examples, showing actual and magnified views:
Example 1


Example 2
Note the truly coincident vertex along the boundary, which remains unchanged in the magnified view.


Example 3


Magnify Topology can also be used to detect and visualized differences between similar geometries (sort of like a visual geometric diff) Here's a contrived example, showing two copies of a JTS logo, in which one copy has two tiny discrepancies (in the 15th decimal place!):

Here's a more realistic real-world example:


This feature will be released in the next version of JTS. In the meantime it's available in the JTS SVN.
Monday, 2 August 2010
Cloudy Blogs
In order to try and keep abreast of the most far-reaching change to IT and computing since the invention of the PC (or the Internet, or time-sharing, or LSI, or solid-state, or commercial computing, or binary logic...), I have inaugurated a Blog Roll for sites which focus on cloud computing (in all its myriad and ever-changing forms...)
See Cloudy Blog Roll in the RH side bar --->
See Cloudy Blog Roll in the RH side bar --->
Friday, 9 July 2010
Is JSON the CSV of the 21st Century?
It strikes me that JSON might be the CSV of the 21st century. Consider these similarities:
CSV has stood the test of time extraordinarily well. According to good 'ol Wikipedia it's been around since at least 1967 - that's over 40 years!

And CSV is still well supported whereever tabular data is used. Let's see if JSON is still around in 2035... I suspect not, because the half-life of technologies is a lot shorter these days. (Maybe CSV is the stromatolite of file formats!)

It would be nice if JSON had a standard schema notation. (There is JSON-Schema. It copies the XML Schema idea of encoding the schema in JSON. It remains to be seen whether this makes it as easy to use and popular as XML Schema has been. 8^)
And why, o why, do field names have to be in quotes? Ok, I know why technically - they're just strings, and JSON strings need to be in quotes, because they need to be embeddable in JavaScript code. But this is a classic case of a vestigial artifact which has a detrimental effect in a new environment. Nobody should be evaling JSON as just another chunk of Javascript anyway, for obvious security reasons. And in the wider world of JSON use cases following Javascript synax is completely irrelevant.
YAML seems to have a lot advantages over JSON as a rich textual format. For instance, it has minimal use of quotes, and a richer, extensible set of datatypes including timestamps and binary (WKB, anyone?). But it's going to be pretty hard to dislodge JSON, which is solidly entrenched for all the wrong reasons.
- They both use POT (plain old text) as their encoding
- The basic datatypes are strings and numbers. JSON adds booleans and nulls - Yay for progress!
- The only schema metadata supported is field names
CSV has stood the test of time extraordinarily well. According to good 'ol Wikipedia it's been around since at least 1967 - that's over 40 years!
And CSV is still well supported whereever tabular data is used. Let's see if JSON is still around in 2035... I suspect not, because the half-life of technologies is a lot shorter these days. (Maybe CSV is the stromatolite of file formats!)
It would be nice if JSON had a standard schema notation. (There is JSON-Schema. It copies the XML Schema idea of encoding the schema in JSON. It remains to be seen whether this makes it as easy to use and popular as XML Schema has been. 8^)
And why, o why, do field names have to be in quotes? Ok, I know why technically - they're just strings, and JSON strings need to be in quotes, because they need to be embeddable in JavaScript code. But this is a classic case of a vestigial artifact which has a detrimental effect in a new environment. Nobody should be evaling JSON as just another chunk of Javascript anyway, for obvious security reasons. And in the wider world of JSON use cases following Javascript synax is completely irrelevant.
YAML seems to have a lot advantages over JSON as a rich textual format. For instance, it has minimal use of quotes, and a richer, extensible set of datatypes including timestamps and binary (WKB, anyone?). But it's going to be pretty hard to dislodge JSON, which is solidly entrenched for all the wrong reasons.
Tuesday, 15 June 2010
Improving DoubleDouble performance with self-modifying methods
In a previous post I discussed how the DoubleDouble extended-precision API provides more robust computation for the Delaunay inCircle test. Quite rightly there were questions about the performance impact of using DoubleDouble. Of course, there is a performance penalty, but it's not as large as you might think, since the inCircle computation is only a portion of the cost of the overall Delaunay algorithm . For larger datasets the performance penalty is about 2x - which seems like an acceptable tradeoff for obtaining robust computation.
But after a bit of thought I realized that there was a simple way to improve the performance of using DoubleDouble. I originally designed the DoubleDouble API to provide value semantics, since this is a 100% safe way of evaluating expressions. However, this requires creating a new object to contain the results of every operation. The alternative is to provide self-modifying methods, which update the value of the object the method is called on. In many arithmetic expressions, it's possible to use self-methods for most operations. This avoids a lot of object instantiation and provides a significant performance benefit (even with Java's ultra-efficient object allocation code).
I added self-method versions of all the basic operations to the DoubleDouble API. While I was at it I threw in operations which took double arguments as well, since this is a common use case and allows avoiding even more allocations (as well as simplifying the code). The self-methods are all prefixed with the word "self", to make them stand out since they are potentially dangerous if used incorrectly. (I suppose a more Java-esque term would be "this-methods", but in this case the Smalltalk argot seems more elegant).
I also decided to rename the class to DD, to improve the readability of the code. Another enhancement might be to shorten the method names to 3 characters (e.g. "mul" instead of "multiply").
As an example, here's the inCircle code in the original implementation and using the improved API. Note the use of the new DD.sqr(double) function to improve readability as well as performance.
Original code
Improved code
The table below summarizes the performance increase provided by using self-methods for inCircle. The penalty for using DD for improved robustness is now down to only about 1.5x slowdown.
Timings for Delaunay triangulation using inCircle predicate implemented using double-precision (DP), DoubleDouble (DD), and DoubleDouble with in-place operations (DD-self). All times in milliseconds.
But after a bit of thought I realized that there was a simple way to improve the performance of using DoubleDouble. I originally designed the DoubleDouble API to provide value semantics, since this is a 100% safe way of evaluating expressions. However, this requires creating a new object to contain the results of every operation. The alternative is to provide self-modifying methods, which update the value of the object the method is called on. In many arithmetic expressions, it's possible to use self-methods for most operations. This avoids a lot of object instantiation and provides a significant performance benefit (even with Java's ultra-efficient object allocation code).
I added self-method versions of all the basic operations to the DoubleDouble API. While I was at it I threw in operations which took double arguments as well, since this is a common use case and allows avoiding even more allocations (as well as simplifying the code). The self-methods are all prefixed with the word "self", to make them stand out since they are potentially dangerous if used incorrectly. (I suppose a more Java-esque term would be "this-methods", but in this case the Smalltalk argot seems more elegant).
I also decided to rename the class to DD, to improve the readability of the code. Another enhancement might be to shorten the method names to 3 characters (e.g. "mul" instead of "multiply").
As an example, here's the inCircle code in the original implementation and using the improved API. Note the use of the new DD.sqr(double) function to improve readability as well as performance.
Original code
public static boolean isInCircleDDSlow(
Coordinate a, Coordinate b, Coordinate c,
Coordinate p) {
DD px = DD.valueOf(p.x);
DD py = DD.valueOf(p.y);
DD ax = DD.valueOf(a.x);
DD ay = DD.valueOf(a.y);
DD bx = DD.valueOf(b.x);
DD by = DD.valueOf(b.y);
DD cx = DD.valueOf(c.x);
DD cy = DD.valueOf(c.y);
DD aTerm = (ax.multiply(ax).add(ay.multiply(ay)))
.multiply(triAreaDDSlow(bx, by, cx, cy, px, py));
DD bTerm = (bx.multiply(bx).add(by.multiply(by)))
.multiply(triAreaDDSlow(ax, ay, cx, cy, px, py));
DD cTerm = (cx.multiply(cx).add(cy.multiply(cy)))
.multiply(triAreaDDSlow(ax, ay, bx, by, px, py));
DD pTerm = (px.multiply(px).add(py.multiply(py)))
.multiply(triAreaDDSlow(ax, ay, bx, by, cx, cy));
DD sum = aTerm.subtract(bTerm).add(cTerm).subtract(pTerm);
boolean isInCircle = sum.doubleValue() > 0;
return isInCircle;
}
Improved code
public static boolean isInCircleDDFast(
Coordinate a, Coordinate b, Coordinate c,
Coordinate p) {
DD aTerm = (DD.sqr(a.x).selfAdd(DD.sqr(a.y)))
.selfMultiply(triAreaDDFast(b, c, p));
DD bTerm = (DD.sqr(b.x).selfAdd(DD.sqr(b.y)))
.selfMultiply(triAreaDDFast(a, c, p));
DD cTerm = (DD.sqr(c.x).selfAdd(DD.sqr(c.y)))
.selfMultiply(triAreaDDFast(a, b, p));
DD pTerm = (DD.sqr(p.x).selfAdd(DD.sqr(p.y)))
.selfMultiply(triAreaDDFast(a, b, c));
DD sum = aTerm.selfSubtract(bTerm).selfAdd(cTerm).selfSubtract(pTerm);
boolean isInCircle = sum.doubleValue() > 0;
return isInCircle;
}
The table below summarizes the performance increase provided by using self-methods for inCircle. The penalty for using DD for improved robustness is now down to only about 1.5x slowdown.
Timings for Delaunay triangulation using inCircle predicate implemented using double-precision (DP), DoubleDouble (DD), and DoubleDouble with in-place operations (DD-self). All times in milliseconds.
| # pts | DP | DD-self | DD |
|---|---|---|---|
| 1,000 | 30 | 47 | 80 |
| 10,000 | 334 | 782 | 984 |
| 10,000 | 7953 | 12578 | 16000 |
Wednesday, 9 June 2010
Improvements to robustness in JTS Delaunay Triangulation
JTS 1.11 added the capability to compute Delaunay Triangulations of point sets. Although the triangulation code was extensively tested and used prior to release, it unfortunately didn't take long before someone uncovered a robustness issue. The problem occurred in a large dataset of over 288,000 points. When the JTS 1.11 Delaunay algorithm was run against this data, a TopologyException was thrown, preventing the computation from completing.
Here's a portion of the dataset which produced the problem:

Digging into the code , it turned out (not unexpectedly) to be caused by a robustness failure in the inCircle predicate. InCircle is a key test used in Delaunay triangulation. The standard algorithm for computing it involves determining the sign of the determinant of a 4x4 matrix.
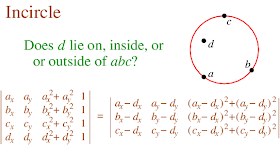
This computation is notoriously prone to robustness failure when evaluated using double-precision arithmetic. The rounding errors inherent in using double-precision can cause the sign of the determinant to be computed incorrectly. (For an good explanation of the issue see this page by Jonathan Shewchuk.)
As a concrete example, consider testing whether the point
POINT (687958.13 7460720.99)
lies in the circumcircle of the triangle
POLYGON ((687958.05 7460725.97, 687957.43 7460725.93, 687957.58 7460721, 687958.05 7460725.97)
Visually this looks like: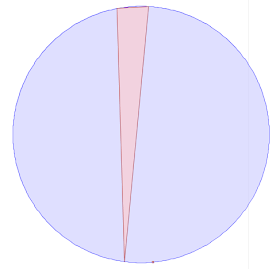
Zooming in, you can see that the query point is NOT in the circumcircle, so that InCircle()=FALSE.
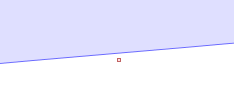 However, evaluating the inCircle predicate determinant using double-precision computes InCircle()=TRUE. This is because the large magnitude of the ordinate values relative to the size of the triangle causes the significant information to be lost in the roundoff error. The effect of this error propagates through the Delaunay algorithm. Ultimately this results in a convergence failure which is detected and reported.
However, evaluating the inCircle predicate determinant using double-precision computes InCircle()=TRUE. This is because the large magnitude of the ordinate values relative to the size of the triangle causes the significant information to be lost in the roundoff error. The effect of this error propagates through the Delaunay algorithm. Ultimately this results in a convergence failure which is detected and reported.
Luckily, a solution was immediately to hand, in the form of the DoubleDouble extended-precision library I ported to Java a while ago. Re-implementing the predicate evaluation using DoubleDouble computed the correct results for inCircle in all cases. This eliminated the robustness failure, and allowed the Delaunay Triangulation of the entire 288K point dataset to be computed without errors (for the record, this took 5 min 20 s).
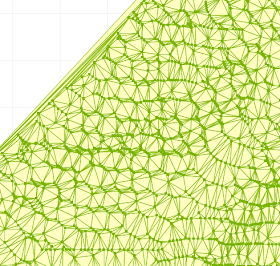
The DoubleDouble code had been a solution in search of a problem for quite a while, so I was happy to get to prove its usefulness in a real-world situation.
And the story doesn't end there - it gets even better...
Here's a portion of the dataset which produced the problem:

Digging into the code , it turned out (not unexpectedly) to be caused by a robustness failure in the inCircle predicate. InCircle is a key test used in Delaunay triangulation. The standard algorithm for computing it involves determining the sign of the determinant of a 4x4 matrix.
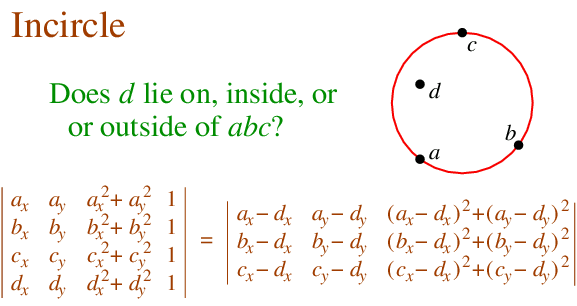
This computation is notoriously prone to robustness failure when evaluated using double-precision arithmetic. The rounding errors inherent in using double-precision can cause the sign of the determinant to be computed incorrectly. (For an good explanation of the issue see this page by Jonathan Shewchuk.)
As a concrete example, consider testing whether the point
POINT (687958.13 7460720.99)
lies in the circumcircle of the triangle
POLYGON ((687958.05 7460725.97, 687957.43 7460725.93, 687957.58 7460721, 687958.05 7460725.97)
Visually this looks like:

Zooming in, you can see that the query point is NOT in the circumcircle, so that InCircle()=FALSE.
 However, evaluating the inCircle predicate determinant using double-precision computes InCircle()=TRUE. This is because the large magnitude of the ordinate values relative to the size of the triangle causes the significant information to be lost in the roundoff error. The effect of this error propagates through the Delaunay algorithm. Ultimately this results in a convergence failure which is detected and reported.
However, evaluating the inCircle predicate determinant using double-precision computes InCircle()=TRUE. This is because the large magnitude of the ordinate values relative to the size of the triangle causes the significant information to be lost in the roundoff error. The effect of this error propagates through the Delaunay algorithm. Ultimately this results in a convergence failure which is detected and reported.Luckily, a solution was immediately to hand, in the form of the DoubleDouble extended-precision library I ported to Java a while ago. Re-implementing the predicate evaluation using DoubleDouble computed the correct results for inCircle in all cases. This eliminated the robustness failure, and allowed the Delaunay Triangulation of the entire 288K point dataset to be computed without errors (for the record, this took 5 min 20 s).

The DoubleDouble code had been a solution in search of a problem for quite a while, so I was happy to get to prove its usefulness in a real-world situation.
And the story doesn't end there - it gets even better...
Thursday, 6 May 2010
More Random Points in JTS
In my last post I talked about the request on the PostGIS list for a function to generate dot-density maps, and about a JTS class to implement it.
Currently the JTS implementation uses purely random points. Here's what a field of purely random points looks like:

As a few people pointed out, and as is obvious from the image, this doesn't look that great, since there tends to be a lot of clusters and blank areas. This doesn't give a very aesthetic effect when used for cartographic purposes.
So I experimented with a few other options.
Here's random points generated in a grid of cells (one point randomly located in each cell). Better, but there are still clusters and blank areas.

Following an idea by Paul Ramsey, here's a grid where the random points are located in circles centred on each grid cell. This is an improvementl, but still doesn't prevent points from ending up close together.
 Next idea: use square cells, but add a "gutter" between each cell. No points are created in the gutter, ensuring that points cannot be closer than the gutter width. In this image the gutter width is 30% of the overall cell width.
Next idea: use square cells, but add a "gutter" between each cell. No points are created in the gutter, ensuring that points cannot be closer than the gutter width. In this image the gutter width is 30% of the overall cell width.

Much better, I think. Although, as the gutter size increases, the underlying grid becomes apparent. Here's a 50% gutter:
 Maybe's there's still improvements that can be made.... It would be nice to avoid the grid effect, and also to reduce the use of a gutter (which skews the density of the distribution).
Maybe's there's still improvements that can be made.... It would be nice to avoid the grid effect, and also to reduce the use of a gutter (which skews the density of the distribution).
As David William Bitner pointed out, these can all be restricted to polygonal areas by simply intersecting the point field with the polygon.
Currently the JTS implementation uses purely random points. Here's what a field of purely random points looks like:

As a few people pointed out, and as is obvious from the image, this doesn't look that great, since there tends to be a lot of clusters and blank areas. This doesn't give a very aesthetic effect when used for cartographic purposes.
So I experimented with a few other options.
Here's random points generated in a grid of cells (one point randomly located in each cell). Better, but there are still clusters and blank areas.

Following an idea by Paul Ramsey, here's a grid where the random points are located in circles centred on each grid cell. This is an improvementl, but still doesn't prevent points from ending up close together.
 Next idea: use square cells, but add a "gutter" between each cell. No points are created in the gutter, ensuring that points cannot be closer than the gutter width. In this image the gutter width is 30% of the overall cell width.
Next idea: use square cells, but add a "gutter" between each cell. No points are created in the gutter, ensuring that points cannot be closer than the gutter width. In this image the gutter width is 30% of the overall cell width.
Much better, I think. Although, as the gutter size increases, the underlying grid becomes apparent. Here's a 50% gutter:
 Maybe's there's still improvements that can be made.... It would be nice to avoid the grid effect, and also to reduce the use of a gutter (which skews the density of the distribution).
Maybe's there's still improvements that can be made.... It would be nice to avoid the grid effect, and also to reduce the use of a gutter (which skews the density of the distribution).As David William Bitner pointed out, these can all be restricted to polygonal areas by simply intersecting the point field with the polygon.
Random Points in Polygon in JTS
Recently there was a thread on the PostGIS list about how to create "dot-density" maps. Essentially this involves creating a set of N randomly-placed points which lie within a given polygon.
JTS already has a lot of random shape creation functions provided in the TestBuilder (randomPoints, randomPointsInGrid, randomRadialPoints, randomRectilinearWalk, etc). But they aren't currently exposed as a class in the API. This seemed like a good use case to initiate the development of such a class.
So now JTS has a RandomShapeFactory class. The class allows setting an extent using either a rectangular Envelope or a polygonal geometry, and will create sets of N points within the defined extent.
Here's a screenshot of the TestBuilder showing the new function at work:
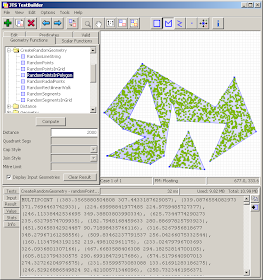
Update: it's been pointed out that what is really desired is to have the points evenly distributed through the polygon. This will take a bit more thinking... At least the API won't have to change much to support this.
JTS already has a lot of random shape creation functions provided in the TestBuilder (randomPoints, randomPointsInGrid, randomRadialPoints, randomRectilinearWalk, etc). But they aren't currently exposed as a class in the API. This seemed like a good use case to initiate the development of such a class.
So now JTS has a RandomShapeFactory class. The class allows setting an extent using either a rectangular Envelope or a polygonal geometry, and will create sets of N points within the defined extent.
Here's a screenshot of the TestBuilder showing the new function at work:

Update: it's been pointed out that what is really desired is to have the points evenly distributed through the polygon. This will take a bit more thinking... At least the API won't have to change much to support this.
Monday, 26 April 2010
Late night link roundup
Here's a few interesting links that occupied my late-night browsing...
Facebook's Graph API: The Future Of Semantic Web?
This is interesting for two reasons. One is that this is a hardball play by Facebook to subvert many other sites whose business model is linking social networking to categories of cultural artifacts. The other is the implications for the Semantic Web. I'm not so sure that the latter is quite so easily accomplished, but perhaps the 80-20 rule will truly turn out to be key here.
Mahout 0.3: Open Source Machine Learning
Neat stuff. Pulls together some fascinating technologies like Hadoop and clustering techniques. Perhaps the best thing about this is the chance to learn more about how this stuff actually works in practice. It would be great if there's a spatial component to this.
Colt - a set of Open Source Libraries for High Performance Scientific and Technical Computing in Java. One more nail in the old "Java is too slow" canard.
Facebook's Graph API: The Future Of Semantic Web?
This is interesting for two reasons. One is that this is a hardball play by Facebook to subvert many other sites whose business model is linking social networking to categories of cultural artifacts. The other is the implications for the Semantic Web. I'm not so sure that the latter is quite so easily accomplished, but perhaps the 80-20 rule will truly turn out to be key here.
Mahout 0.3: Open Source Machine Learning
Neat stuff. Pulls together some fascinating technologies like Hadoop and clustering techniques. Perhaps the best thing about this is the chance to learn more about how this stuff actually works in practice. It would be great if there's a spatial component to this.
Colt - a set of Open Source Libraries for High Performance Scientific and Technical Computing in Java. One more nail in the old "Java is too slow" canard.
Wednesday, 7 April 2010
Twitter heart JTS
At least, that's what it looks like from their presentation on Handling Real-Time Datastreams at the recent Where 2.0.
They note that JTS does not have support for GeoRSS or GeoJSON. Actually there is a GeoJSON implementation sitting in the labs - but it really needs some funding to get it finished off (hint, hint, Twitter - what, you think this groovy open-source spatial stuff just codes itself?)
And as usual people have not noticed that the real source for JTS information is on the new home page and the Sourceforge site - not this stale web page. Sigh... if only URLs had expiry dates.
They note that JTS does not have support for GeoRSS or GeoJSON. Actually there is a GeoJSON implementation sitting in the labs - but it really needs some funding to get it finished off (hint, hint, Twitter - what, you think this groovy open-source spatial stuff just codes itself?)
And as usual people have not noticed that the real source for JTS information is on the new home page and the Sourceforge site - not this stale web page. Sigh... if only URLs had expiry dates.

Wednesday, 10 March 2010

Tuesday, 9 March 2010
More Open-Source Geocoders
To continue my previous post on open-source geocoders, here's a few more geocoding projects we've reviewed here at Refractions:
References
[1] A probabilistic geocoding system utilising a parcel based address file; CHRISTEN Peter, WILLMORE Alan, CHURCHES Tim; Data mining : ( theory, methodology, techniques, and applications ), 2006
- PAGC Postal Address GeoCoder ( ) is "a library and a CGI based web service written in ANSI C that uses an address-ranged street network shapefile". It uses a rule-based parser based on the Aho-Corasick string searching algorithm. The parser rules are user-configurable, which is nice (although the rule format is NON-user-friendly, consisting of opaque lists of integers!). Exact match, Soundex and Edit distance are used in the matching phase. Supported reference road networks include both the TIGER and the StatsCan networks. BerkeleyDB is used as the reference network data store.
- The USC WebGIS Geocoder provides a free, size-limited geocoding service. It claims to be open source, however links to the source code are not obviously provided. It is documented as using a "rule-based parser", but it's not clear how a user could actually customize this and run their own instance. Matching uses attribute relaxation, substring matching, and Soundex. The reference dataset appears to be TIGER, stored in a MS SQLServer database.
- The FEBRL Geocoder is a well-researched, well-documented system implemented in Python. It targets Australian road network data. It specifically does not attempt to work with North American data (but suggests that the address models are close enough that this would be possible.) The address parser is unique in using a trainable Hidden Markov Model, and also in being documented by a series of academic papers (e.g. [1] ) describing the approach in detail. An address cleaning module is supplied. Matching uses exact or "approximate matching".
- The OpenGeocoder initiative appears to be a worthy attempt to create a geocoder under the auspices of OpenGeo (possibly as a port of PAGC?). However, this project has not had much recent activity, and doesn't appear to provide any actual code.
References
[1] A probabilistic geocoding system utilising a parcel based address file; CHRISTEN Peter, WILLMORE Alan, CHURCHES Tim; Data mining : ( theory, methodology, techniques, and applications ), 2006
Saturday, 6 March 2010
Open Source Geocoders
One of the more interesting projects we have going on here at Refractions is to build a geocoder for use in a crime-mapping application we are developing for a client. We do have an existing geocoder codebase developed for another project. But we're not 100% happy with its performance and customizability, so we decided to look into developing a new library specifically for this project.
Of course the first thing we did was carry out a technology review of all the open-source geocoders we could find. Here's a list of all the ones we looked at:
Some observations:
Of course the first thing we did was carry out a technology review of all the open-source geocoders we could find. Here's a list of all the ones we looked at:
- Geo-Coder-US - A Perl module developed by the ubiquitous Schuyler Erle. "For geocoding US addresses, that is, estimating the latitude and longitude of any street address or intersection in the United States, using the TIGER/Line data set". Probably no longer being developed, since it has been superseded by
- GeoCommons Geocoder::US - a rewrite of Geo-Coder-US into Ruby (and also requiring C and SQLite). "Although it is primarily intended for use with the US Census Bureau’s free TIGER/Line dataset, it uses an abstract US address data model that can be employed with other sources of US street address range data"
- JGeoCoder - A Java API loosely modelled after Geo::Coder::US. Works against a SQL database loaded with TIGER data (an H2 image is supplied). Last activity in 2008.
- Explorer GeoCoder by SRC - A C++ library for "a data and country independent geocoding engine" which can "assign latitude and longitude coordinates to any United States street address or intersection". Has an active mailing list.
- Frost Tiger Geocoder by Stephen Frost et al - a Postgres SQL library for geocoding against TIGER data
Some observations:
- All of the engines implement parsing and matching logic purely in code. None of them provide a declarative description language to allow easy modification of parsing, standardization, and matching rules. (To be fair, this is bit of a tall order. And it's not clear that it's even possible to provide an understandable declarative language for the fully general case. For example, the ArcMap geocoder (which appears to be the old MatchWare engine) provides a geocoding definition language (actually 5 different ones) - but the languages look scarily complex! Nonetheless, this is an important feature for easy of maintenance and customization.)
- JGeoCoder uses a large number of complex regular expressions to perform parsing. This looks like it would be difficult to customize, due to the well-known opaqueness of large REs, and perhaps also to the relative inflexibility of the RE paradigm
- The GeoCoder::US Ruby module seems to be the simplest code base. (I ended up almost understanding its parsing algorithm 8^) It uses REs, but in a saner amount. However, it's unclear how well it deals with erroneous input data, and how easy it would be to modify for a different address model.
- The Explorer geocoder uses a large amount of fairly complex C++ code. It also looked quite challenging to understand and modify.
- In all the projects the parser design appears to be fairly ad-hoc and poorly documented. This situation doesn't inspire confidence that it would be possible to modify the parser to support a different address model, or to handle particular kinds of input errors. (GeoCoder::US is a possible exception to this - it has a relatively simple parsing algorithm with at least some documentation).
Monday, 1 March 2010
JTS Version 1.11 released!
JTS Version 1.11 is now available for download from SourceForge.

The version contains numerous enhancements, including
Full release notes:

The version contains numerous enhancements, including
- Delaunay triangulation and Voronoi diagrams
- AWT Shape reading and writing
- Geometry similarity metrics
- support for Geometry densification
- Numerous improvements to the JTS TestBuilder
Full release notes:
Functionality Improvements
- Added CoordinateArrays.isRing
- Added CGAlgorithms.signedArea(CoordinateSequence)
- Added CoordinateArrays.copyDeep(...) method to copy sections of arrays
- Added CoordinateList.add(Coordinate[], boolean, int, int) method to add sections of arrays
- Added LineSegment.toGeometry(), LineSegment.lineIntersection()()
- Added LineSegment.hashCode()
- Added geometric similarity classes (HausdorffSimilarityMeasure, AreaSimilarityMeasure)
- Added MinimumDiameter.getMinimumRectangle()
- Added MinimumBoundingCircle class
- Added Densifier class
- Added triangulation API, including QuadEdgeSubdivision, IncrementalDelaunayTriangulator, ConformingDelaunayTriangulator and supporting classes
- Added VoronoiDiagramBuilder to perform Voronoi diagram generation
- Added scaleInstance(scaleX, scaleY, x, y) to AffineTransformation
- Added AffineTransformationFactory to allow generating transformations from various kinds of control inputs
- Added BinTree.remove() method
- Fixed BinTree.query() to allow null interval arguments
- Added ShapeReader API to convert Java2D Shapes into JTS Geometry
- Added ShapeWriter API to convert JTS geometry into Java2D Shapes
- Added FontGlyphReader API to render Java2D text font glyphs into geometry
- Added SdeReader to jtsio library
- Added Debug break methods
- Added Memory utility for reporting memory statistics
- Added ObjectCounter utility for counting objects
- Added createSquircle and createSuperCircle to GeometricShapeFactory
Performance Improvements
- Improved performance of Geometry.getArea() and Geometry.getLength() when used with custom CoordinateSequences
API Changes
- Deprecated WKBWriter.bytesToHex in favour of WKBWriter.toHexto regularize and simplify method name
Bug Fixes
- Fixed Point.isValid() to check for invalid coordinates (ie with Nan ordinates)
- Fixed Geometry.distance() and DistanceOp to return 0.0 for empty inputs
- Fixed Buffer to handle degenerate polygons with too few distinct points correctly
- Added illegal state check in LineSegment.pointAlongOffset()
- Fixed exception strategy in BufferSubgraph to handle certain robustness failures correctly
- Fixed robustness problem in OffsetCurveBuilder in computing mitred joins for nearly parallel segments
- Fixed minor bug in BufferInputLineSimplifier which prevented simplification of some situations
- Fixed bug in BufferInputLineSimplifier which caused over-simplification for large tolerances
- Fixed bug in Angle.normalizePositive to handle values > 2PI correctly
- Fixed WKTWriter to emit correct syntax for MULTIPOINTs
- Fixed WKTReader to accept correct syntax for MULTIPOINTs
- CGAlgorithms.isCCW now checks for too few points in the ring and throws an IllegalArgumentException
- Fixed bug in AffineTransformation#eqals (logic bug)
- Fixed bug in CoordinateList#closeRing (cloning closing Coordinate)
JTS TestBuilder
Functionality Improvements
- WKT input is cleaned automatically when loaded (illegal chars are removed)
- Added WKT-Formatted option to Test Case View dialog
- Many new geometry functions added
- Geometry functions are displayed in tree
- Geometry functions can be implemented as Java static class methods.
- Geometry function classes can be loaded dynamically from command-line
- Improved handling of very large geometry inputs and results
- Threaded rendering allows display of very large geometries without limiting usability
- Added Draw Rectangle tool
- Added Drag-n-drop loading of .SHP files
- Added Info tool to provide persistent display of geometry point/segment information
- Added display of memory usage
Wednesday, 17 February 2010
JTS and Google App Engine
Nice to see that JTS is officially certified as compatible with Google App Engine.
 JTS makes clouds easy!
JTS makes clouds easy!
A few people have tinkered with running JTS in GAE (eg here and here). But the killer app has yet to emerge... How about a Java-based App Engine version of this?
 JTS makes clouds easy!
JTS makes clouds easy!A few people have tinkered with running JTS in GAE (eg here and here). But the killer app has yet to emerge... How about a Java-based App Engine version of this?
JTS & Jython
Sean's post suddenly made me realize that it might be really cool to have a nice set of Jython bindings for JTS (a la what Shapely has done for GEOS).
Now, of course Jython can call Java classes directly, so maybe this is an empty task. But perhaps there are some impedance mismatches which could be removed via some simple glue code. And it would be nice to provide some examples of Jython code using JTS, to make it easier for people to figure out how to get started.
And of course I'd throw in Proj4J as well!
One more thing for my ever-growing task list...
If anyone has any ideas on what needs doing here, I'd like to hear them.
(This also makes me think that both Jython and JTS need some cool logos... I don't have any pictures to post!)
Now, of course Jython can call Java classes directly, so maybe this is an empty task. But perhaps there are some impedance mismatches which could be removed via some simple glue code. And it would be nice to provide some examples of Jython code using JTS, to make it easier for people to figure out how to get started.
And of course I'd throw in Proj4J as well!
One more thing for my ever-growing task list...
If anyone has any ideas on what needs doing here, I'd like to hear them.
(This also makes me think that both Jython and JTS need some cool logos... I don't have any pictures to post!)
Friday, 5 February 2010
Opposites attract?
This sounds like
Fine Swiss shade-grown organic chocolate and rancid peanut butter from the big-box store discount aisle
Fine Swiss shade-grown organic chocolate and rancid peanut butter from the big-box store discount aisle
HatBox for Derby and H2
I just saw the HatBox spatial extension to Derby and H2. (Cute name - Derby, HatBOX - get it?)

And of course HatBox uses JTS!
This is great - H2 is a fantastic pure Java database, which has been crying out for spatial support. (Perhaps if this extension proves its worth it will be merged into the main H2 codebase at some point?)
However, HatBox is still a "user-space extension" - which means that it has not enhanced the SQL evaluation engine itself with knowledge about spatial indexes and when to use them. So to utilize spatial indexing you have to explicitly join to the spatial index table, which results in ugly SQL like this:
This is the same approach used in Sqlite and ESRI SDE and other spatial extensions which operate in user space rather than DB engine space (Mike Butler of SDBE fame used to call this "staying above the blood-brain barrier" 8^). Basically you are adding the index filter condition which for scalar indexes the SQL engine adds automatically.
In contrast, the "big boys" like PostGIS, Oracle, SQL Server, DB2, Informix, etc have actually extended their database engine to handle spatial datatypes and indexes. Most of these systems actually have provided a general extensibility mechanism which allows a clean separation between the engine core and the new datatypes. PostgreSQL is probably the one which takes this to the ultimate extent.
User-space spatial extensions are for a first approach, but it would be really nice to be able to play with the big boys and incorporate knowledge of spatial indexes and functions directly into the database engine. This should be easierto do in Java than in C - are you listening, H2?
And of course HatBox uses JTS!
This is great - H2 is a fantastic pure Java database, which has been crying out for spatial support. (Perhaps if this extension proves its worth it will be merged into the main H2 codebase at some point?)
However, HatBox is still a "user-space extension" - which means that it has not enhanced the SQL evaluation engine itself with knowledge about spatial indexes and when to use them. So to utilize spatial indexing you have to explicitly join to the spatial index table, which results in ugly SQL like this:
select ID, GEOM from T1 as t
inner join
HATBOX_MBR_INTERSECTS_ENV('PUBLIC','T1',145.05,145.25,-37.25,-37.05) as i
on t.ID = i.HATBOX_JOIN_ID
This is the same approach used in Sqlite and ESRI SDE and other spatial extensions which operate in user space rather than DB engine space (Mike Butler of SDBE fame used to call this "staying above the blood-brain barrier" 8^). Basically you are adding the index filter condition which for scalar indexes the SQL engine adds automatically.
In contrast, the "big boys" like PostGIS, Oracle, SQL Server, DB2, Informix, etc have actually extended their database engine to handle spatial datatypes and indexes. Most of these systems actually have provided a general extensibility mechanism which allows a clean separation between the engine core and the new datatypes. PostgreSQL is probably the one which takes this to the ultimate extent.
User-space spatial extensions are for a first approach, but it would be really nice to be able to play with the big boys and incorporate knowledge of spatial indexes and functions directly into the database engine. This should be easierto do in Java than in C - are you listening, H2?
Tuesday, 2 February 2010

Saturday, 30 January 2010
Announcing Proj4J
It's been a while since I posted anything, because like a true programmer I've been too busy cutting code to write about it. Time to catch up!
My main focus for a while has been working on a Java port of the popular PROJ.4 projection library. This was motivated by finding the great work that JHLabs started with his JavaProj port. That seemed too good to be left to languish, so I dusted it off and started to clean it up. The library is now known as Proj4J. It has been substantially reworked to provide a more functional API and a cleaner codebase. Various bug fixes have been made to the core projections (although more remains to do!), and a formal test suite has been added.
To answer the question of "Why another Java projection library?", the main reason is that PROJ.4 is popular, well-tested and well-documented, so it seems like a good idea to make it available in the Java world. Other goals include creating a small, easy-to-understand, easy-to-use library, which can be embedded and/or extended as desired by small projects. A personal goal is to provide coordinate system transformation services in JEQL (which is now realized by exposing Proj4J via JEQL functions).
OSGeo is hosting the codebase as part of the MetaCRS umbrella project. There it lives in the good company of Proj4JS, CS-MAP, spatialreference.org and of course PROJ.4.
The code is shaping up nicely for a 1.0 release. It can also be downloaded and used as it stands. Check it out! Even better, contribute some tests and bug fixes!
 Wagner VII Projection
Wagner VII Projection
My main focus for a while has been working on a Java port of the popular PROJ.4 projection library. This was motivated by finding the great work that JHLabs started with his JavaProj port. That seemed too good to be left to languish, so I dusted it off and started to clean it up. The library is now known as Proj4J. It has been substantially reworked to provide a more functional API and a cleaner codebase. Various bug fixes have been made to the core projections (although more remains to do!), and a formal test suite has been added.
To answer the question of "Why another Java projection library?", the main reason is that PROJ.4 is popular, well-tested and well-documented, so it seems like a good idea to make it available in the Java world. Other goals include creating a small, easy-to-understand, easy-to-use library, which can be embedded and/or extended as desired by small projects. A personal goal is to provide coordinate system transformation services in JEQL (which is now realized by exposing Proj4J via JEQL functions).
OSGeo is hosting the codebase as part of the MetaCRS umbrella project. There it lives in the good company of Proj4JS, CS-MAP, spatialreference.org and of course PROJ.4.
The code is shaping up nicely for a 1.0 release. It can also be downloaded and used as it stands. Check it out! Even better, contribute some tests and bug fixes!
 Wagner VII Projection
Wagner VII Projection