The previous post discussed polygonal coverages and outlined the plan to support them in the JTS Topology Suite. This post presents the first step of the plan: algorithms to validate polygonal coverages. This capability is essential, since coverage algorithms rely on valid input to provide correct results. And as will be seen below, coverage validity is usually not obvious, and cannot be taken for granted.
As described previously, a polygonal coverage is a set of polygons which fulfils a specific set of geometric conditions. Specifically, a set of polygons is coverage-valid if and only if it satisfies the following conditions:
- Non-Overlapping - polygon interiors do not intersect
- Edge-Matched (also called Vector-Clean and Fully-Noded) - the shared boundaries of adjacent polygons has the same set of vertices in both polygons
The Non-Overlapping condition ensures that no point is covered by more than one polygon. The Edge-Matched condition ensures that coverage topology is stable under transformations such as reprojection, simplification and precision reduction (since even if vertices are coincident with a line segment in the original dataset, this is very unlikely to be the case when the data is transformed).
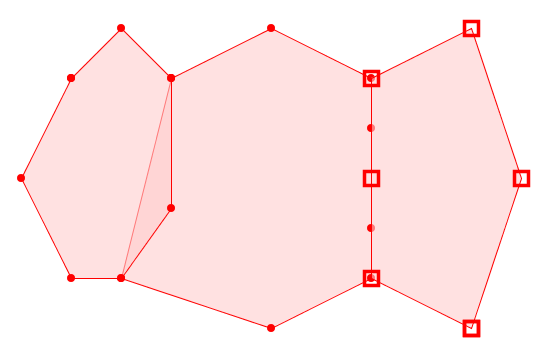
An invalid coverage which violates both (L) Non-Overlapping and (R) Edge-Matched conditions (note the different vertices in the shared boundary of the right-hand pair)
Note that these rules allow a polygonal coverage to cover disjoint areas. They also allow internal gaps to occur between polygons. Gaps may be intentional holes, or unwanted narrow gaps caused by mismatched boundaries of otherwise adjacent polygons. The difference is purely one of size. In the same way, unwanted narrow "gores" may occur in valid coverages. Detecting undesirable gaps and gores will be discussed further in a subsequent post.
Computing Coverage Validation
Coverage validity is a global property of a set of polygons, but it can be evaluated in a local and piecewise fashion. To confirm a coverage is valid, it is sufficient to check every polygon against each adjacent (intersecting) polygon to determine if any of the following invalid situations occur:
- Interiors Overlap:
- the polygon linework crosses the boundary of the adjacent polygon
- a polygon vertex lies within the adjacent polygon
- the polygon is a duplicate of the adjacent polygon
- Edges do not Match:
- two segments in the boundaries of the polygons intersect and are collinear, but are not equal
If neither of these situations are present, then the target polygon is coverage-valid with respect to the adjacent polygon. If all polygons are coverage-valid against every adjacent polygon then the coverage as a whole is valid.
For a given polygon it is more efficient to check all adjacent polygons together, since this allows faster checking of valid polygon boundary segments. When validation is used on datasets which are already clean, or mostly so, this improves the overall performance of the algorithm.
Evaluating coverage validity in a piecewise way allows the validation process to be parallelized easily, and executed incrementally if required.
JTS Coverage Validation
Validation of a single coverage polygon is provided by the JTS
CoveragePolygonValidator class. If a polygon is coverage-invalid due to one or more of the above situations, the class computes the portion(s) of the polygon boundary which cause the failure(s). This allows the locations and number of invalidities to be determined and visualized.
The class
CoverageValidator computes coverage-validity for an entire set of polygons. It reports the invalid locations for all polygons which are not coverage-valid (if any).
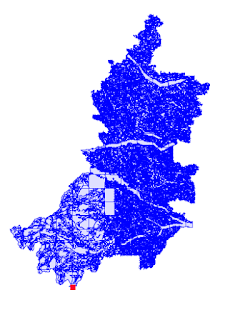
Using spatial indexing makes checking coverage validity quite performant. For example, a coverage containing 91,384 polygons with 10,474,336 vertices took only 6.4 seconds to validate. In this case the coverage is nearly valid, since only one invalid polygon was found. The invalid boundary linework returned by CoverageValidator allows easily visualizing the location of the issue.
A polygonal dataset of 91,384 polygons, containing a single coverage-invalid polygon
The invalid polygon is a tiny sliver, with a single vertex lying a very small distance inside an adjacent polygon. The discrepancy is only visible using the JTS TestBuilder Reveal Topology mode.
The size of the discrepancy is very small. The vertex causing the overlap is only 0.0000000001 units away from being valid:
[921] POLYGON(632)
[922:4] POLYGON(5)
Ring-CW Vert[921:0 514] POINT ( 960703.3910000008 884733.1892000008 )
Ring-CW Vert[922:4:0 3] POINT ( 960703.3910000008 884733.1893000007 )
This illustrates the importance of having fast, robust automated validity checking for polygonal coverages, and providing information about the exact location of errors.
Real-world testing
With coverage validation now available in JTS, it's interesting to apply it to publicly available datasets which (should) have coverage topology. It is surprising how many contain validity errors. Here are a few examples:
This dataset contains 1,498 polygons with 57,632 vertices. There are 379 errors identified, which mainly consist of very small discrepancies between vertices of adjacent polygons.
Example of a discrepant vertex in a polygon
| Source | British Ordnance Survey OpenData |
| Dataset | Boundary-Line |
| File | unitary_electoral_division_region.shp |
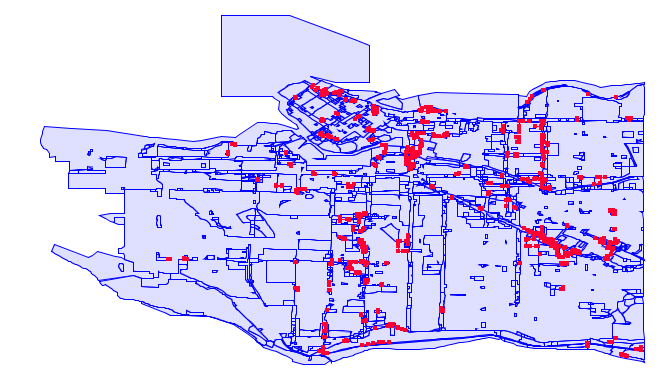
This dataset contains 1,178 polygons with 2,174,787 vertices. There are 51 errors identified, which mainly consist of slight discrepancies between vertices of adjacent polygons. (Note that this does not include gaps, which are not detected by CoverageValidator. There are about 100 gaps in the dataset as well.)
An example of overlapping polygons in the Electoral Division dataset
The dataset (slightly reduced) contains 7 polygons with 18,254 vertices. Coverage validation produces 64 error locations. The errors are generally small vertex discrepancies producing overlaps. Gaps exist as well, but are not detected by the default CoverageValidator usage.
An example of overlapping polygons (and a gap) in the VerwaltungsEinheit dataset
As always, this code will be ported to
GEOS. A further goal is to provide this capability in
PostGIS, since there are likely many datasets which could benefit from this checking. The piecewise implementation of the algorithm should mesh well with the nature of SQL query execution.
And of course the next logical step is to provide the ability to fix errors detected by coverage validation. This is a research project for the near term.
UPDATE: my colleague Paul Ramsey pointed out that he has already
ported this code to GEOS. Now for some performance testing!